The state machines used by LEX and YACC are usually implemented by combining data tables that depend on the user's grammar rules, with a general algorithm that depends only on which tool is in use. (Methods for calculating these tables are beyond the scope of this course unit, but will be covered in CS304 next year.)
state= 0; get next input character
while (not end of input) {
depending on current state and input character
match: /* input expected */
calculate new state; get next input character
accept: /* current pattern completely matched */
state= 0; perform action corresponding to pattern
error: /* input unexpected */
state= 0; echo 1st character input after last accept or error;
reset input to 2nd character input after last accept or error;
}
The decision as to which of the 3 options to choose, and the calculation of
the new state after a match, are encoded in a simple table indexed by the
current state and input character.
The particular regular expressions are converted into a Deterministic FSA
(DFSA) e.g. for a(b|c)d*e+

| a | b | c | d | e | other | |
| 0 | m(1) | |||||
| 1 | m(2) | m(2) | ||||
| 2 | m(2) | m(3) | ||||
| 3 | a | a | a | a | m(3) | a |
Although a simple stack of states is sufficient for the parsing algorithm,
YACC's stack really consists of (state, value) pairs, where the
value is set and used in the actions ($$, $1 etc.).
initialise stack
state= 0; get next input symbol
while (not accept and not error) {
depending on current state and input symbol
shift: /* stack does not yet hold full RHS */
push current state
calculate new state; get next input symbol
reduce: /* input symbol follows a RHS on the stack */
pop RHS /*current state represents right-most item*/
calculate new state using LHS symbol & state from stack
accept: /* i.e. stack empty and end of input */
finish parsing
error: /* input unexpected */
. . .
}
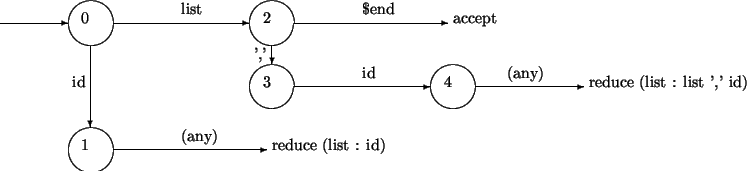
LEX does not make its decision table visible, but YACC
allows us to see it in the file y.output
e.g. here is the (reformatted) y.output
for list : id | list ',' id ;
state 0 $accept : _list $end
id shift 1 . error list goto 2
state 1 list : id_ (1)
. reduce 1
state 2 $accept : list_$end
list : list_, id
$end accept , shift 3 . error
state 3 list : list ,_id
id shift 4 . error
state 4 list : list , id_ (2)
. reduce 2
(for each state, the _ in the first line(s) tell us where we are in
recognising the grammar, and the last line(s) are the transitions to other
states. $end means end of input)
| state | terminal symbols | non-terminals | ||
| id | ',' | $end | list | |
| 0 | 1 | 2 | ||
| 1 | list:id | list:id | list:id | |
| 2 | 3 | accept | ||
| 3 | 4 | |||
| 4 | list:list ',' id | list:list ',' id | list:list ',' id | |
| number = shift to new state | new state | |||
| LHS:RHS = reduction rule | after reduction | |||
| accept | ||||||||||||||||
| accept | ||||||||||||||||
| error | ||||||||||||||||
| error |
list, and 2 respectively).
a , b , c as a list of identifiers. This would be input
by a program generated by LEX (or similar), so the parser would
see the symbols
list : id | list ',' id ;
.... look ahead at id 'a'
id <-- 'a'
|
list
| .... look ahead at ','
| ',' <-- ','
| | .... look ahead at id 'b'
| | id <-- 'b'
+------+------+
list
| .... look ahead at ','
| ',' <-- ','
| | .... look ahead at id 'c'
| | id <-- 'c'
+------+------+
list
| .... look ahead at END
Example parse trace for list : id | id ',' list ;
.... look ahead at id 'a'
id <-- 'a'
| .... look ahead at ','
| ',' <-- ','
| | .... look ahead at id 'b'
| | id <-- 'b'
| | | .... look ahead at ','
| | | ',' <-- ','
| | | | .... look ahead at id 'c'
| | | | id <-- 'c'
| | | | | .... look ahead at END
| | | | list
| | +------+------+
| | list
+------+------+
list
|
The differences arise solely because of the differences in the grammars: as
YACC looks for and reduces the RHSs of the actual grammar rules, with
left-recursion the sub-lists must be on the left of the parse tree, whereas
with right-recursion they must be on the right. Input is left-to-right, so in
the first example the tree can be built as the input is being read,
but in the second example all the input must be read before the tree can start
to be built.
The right recursive grammar uses more stack space (the number of ![]() s on each
line) than the left recursive grammar. This is always the case with LR grammar
tools like YACC, so to minimise the risk of stack overflow we should use left
recursive grammars wherever possible. There are other kinds of grammar
recognising tools for which this is not the case, or which cannot use one or
the other kind of recursion, so check this if you use a tool other than YACC.
s on each
line) than the left recursive grammar. This is always the case with LR grammar
tools like YACC, so to minimise the risk of stack overflow we should use left
recursive grammars wherever possible. There are other kinds of grammar
recognising tools for which this is not the case, or which cannot use one or
the other kind of recursion, so check this if you use a tool other than YACC.
For example, C is not quite LR(1), particularly in the area of declaration processing. One 'fix' is to check any identifier at the start of a statement to see if it is currently defined by a typedef, in which case the statement is a declaration!
-v and
construct the corresponding PDAs from the y.output files.while|if /* keyword */ [a-z]+ /* identifier */Create an NFSA for these regular expressions, and then convert it to an equivalent DFSA that distinguishes between keywords and identifiers.