A translator, whether human or machine, has to understand what it is translating. Because we can normally rely on the common sense and shared experiences of other human beings, natural languages can be ambiguous, fuzzily structured and have large vocabularies.
In contrast, not only do computer languages have limited, mainly user-defined vocabularies, but also we have to exactly specify the legal forms of each construct of the language and what it means, both alone and in combination with every other construct.
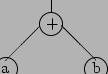
The meaning of a + b is usually along the lines of:
"take the values associated with the identifiers a and b, combine those two
values into one by addition, and have the resulting value ready for further
use"
This typical meaning may be modified in many ways e.g.:
a + b [infix] a b + [postfix/Reverse Polish Notation] + a b [prefix] add a b add (a, b) (add, a, b) add a and b a plus b
Prefix and postfix notations, although awkward to use at first, don't get significantly more complex as expressions get bigger. However, most humans, and therefore most computer languages, use infix notation, and this gives rise to yet more possibilities of representation and meaning as expressions get bigger:
1 + 2 * 3 ?
If we simply obey the expression left-to-right, it means
(1 + 2) * 3 i.e. 9,
but we usually give operators like
* and / higher precedence than operators like
+ and - i.e. they are obeyed first, so the expression means
1 + (2 * 3) i.e. 7.
3 - 2 - 1 ?
What do we do if precedence doesn't resolve the problem i.e. two operators in an expression have the same precedence?
If we obey the example expression left-to-right, it means
(3 - 2) - 1 i.e. 0,
but if we obey it right-to-left it means
3 - (2 - 1) i.e. 2.
With most arithmetic operators
(including -, so the answer is normally 0)
we simply work left-to-right. This is known as left associative.
With some operators we have to work right-to-left (right associative)
e.g. raising to a power - ![]() is just
is just ![]() ,
whereas
,
whereas ![]() is
is ![]() .
.
Some operators are not allowed to be used more than once without explicit
brackets (non-associative)
e.g. 1 <= x <= 10 is illegal in Pascal.
It is legal in C, but is probably not doing what you want (it does
(1 <= x) <= 10). The representation for the intended meaning is
(1 <= x) && (x <= 10). Making <= etc. non-associative in Pascal
means that you can't get the unintended meaning by mistake, although if you
really want something similar you can force it by using extra brackets.
(We will be using the concepts of fix, precedence and associativity in later sections and in the lab.)
Representation is normally referred to as syntax or grammar. There are many different formal notations for describing syntax, most of which are equivalent in descriptive power, although they may vary in how succinct or verbose they are. We will be looking at two different notations (regular expressions and BNF), which have different descriptive powers, and the associated tools for dealing with them, LEX and YACC. These kinds of tools, that convert a grammar into a parser (a program that recognise inputs that match the grammar), are known as parser-generators.
Meaning is normally referred to as semantics (or static semantics). There are formal notations for describing semantics, as you may have seen in CS1112, but we will not be using them. This is because semantics is a much more complex subject than syntax, still an area for much research, and because different programming languages vary much more in semantics than in syntax. Therefore, we will only be looking at one major area of semantics, that of identifiers and the declarations that bind meanings to them in a scope, and one technique for dealing with them, the use of dictionaries.
We will be concentrating mainly on describing and implementing syntax, and we will be looking at this next.
\ ^ $ . [ ] * + ? | ( )
| any non-metacharacter | recognise that character |
\any metacharacter |
recognise that metacharacter |
\n or \t |
as for C - newline or tab |
^ |
beginning of line |
$ |
end of line |
. |
any one character except newline |
[ ] |
any one character from inside the brackets |
indicate ranges by - e.g. [a-zA-Z] |
|
an actual ] must be the first character |
|
an actual - must be the first or last character |
|
[^ ] |
any one character except . . . |
| anything* | anything repeated none or more times |
anything+ |
anything repeated one or more times |
anything? |
anything repeated none or one times |
one | another |
either one or another |
( ) |
recognise the contents |
[ ] ( ), * + ?, concatenation, |
a + b
Recognise and obey commands immediately, as with EGREP and shells/CLIs.
Recognise commands and create an equivalent set of commands in another language (e.g. assembly language), as with compilers. LEX and YACC fall into this category, as they transform the list of patterns into a C program that searches for them in its input.
Sometimes a combination of these approaches is used: commands can be embedded within the piece of text they are designed to act on, so that the commands are interpreted, but give rise to a translation of the input text into some new form. For example, CPP, which deals with commands like "#include" embedded within a C program and outputs a more verbose C program, and LATEX, which reads commands embedded in e.g. English text to generate beautifully formatted documents like this!
man make etc.