



Next: Building a Compiler: recognising
Up: CS2111: Design and Implementation
Previous: Abstract Data-Types, Modules, Classes
Contents
Subsections
Language Design and Implementation - Identifiers
To implement identifiers, we have to take account of their static and
dynamic properties, as described by the static and dynamic environments
(c.f.  13-18). Broadly speaking, we use stack
frames at run-time to implement dynamic environments, and dictionaries at
compile-time to implement static environments. However, as we bind static
objects to dynamic objects we blur this boundary, so that e.g. stack frames
include static links, and dictionaries include run-time addresses.
A dictionary contains a set of names used in a piece of code and, for each
name, information describing their implicit or explicit declarations. To
look up an identifier in a dictionary:
13-18). Broadly speaking, we use stack
frames at run-time to implement dynamic environments, and dictionaries at
compile-time to implement static environments. However, as we bind static
objects to dynamic objects we blur this boundary, so that e.g. stack frames
include static links, and dictionaries include run-time addresses.
A dictionary contains a set of names used in a piece of code and, for each
name, information describing their implicit or explicit declarations. To
look up an identifier in a dictionary:
- locate the particular name (if present)
- using any standard technique, such as B-trees or hashing.
This part of the dictionary is known as the name-list or symbol-table.
- locate (information about) the relevant declaration of the name
- most languages permit multiple scopes and /or multiple meanings for a single
name in a single scope.
This part of the dictionary is known as the property-list(s), of property
entries or properties.
We can either use a single dictionary, containing all the names in the
source text, each linked to whichever declarations are currently valid,
or several dictionaries e.g. 1 per scope and/or per kind of declaration, so
each dictionary contains fewer declarations, or even just one, for each name
in it.
In the former case, we search the dictionary for a name, and then for the
relevant declaration. In the latter case, we search several dictionaries in
turn (e.g. from the current scope outwards) for the name until we find the
declaration we need. As most programs have few nested scopes and few kinds
of declarations, these repeated searches need not be a serious overhead, and
can simplify other actions, such as tidying up at the end of a scope.
In some languages, a new scope starts at each new declaration. This makes
multiple dictionaries harder to use but, worse, complicates the relationship
between the static and dynamic environments. Implementations often coalesce
such scopes to start at e.g. blocks or functions (or even coalesce blocks
into the owning function), but perform extra compile-time and/or run-time
actions to comply with the language design. Languages like SML, where the
same name may be redeclared many times in the same function, cause problems
that I shall not discuss here.
Using a dictionary
- At the start of each new scope (e.g. function or block)
SPMquot "
- Whatever initialisation is necessary.
- At each declaration of an identifier
SPMquot "
- Search the relevant dictionary to find the name in the namelist, and
insert it if missing.
- Check that there is not already a declaration (of the same kind?) for
the name in the scope.
- Insert a new property entry describing the declaration.
If one dictionary holds multiple scopes, insert new entries at the head of
the list of properties for the name, so declarations in scope are found
first.
- At each use of an identifier
SPMquot "
- Search the relevant dictionary (or dictionaries, in sequence) to find
the name, and insert it if missing.
- Find the current declaration in scope (of the correct kind) for that
name, and insert a new property entry if none is found.
- Some languages allow implicit declarations, so they specify default
types etc. Others do not, so we report the error, but generate a property
entry to avoid repeating the error message.
- Some languages expect explicit declarations but allow forward
references i.e. allow an identifier to be used before it is declared. If
the semantics of the forward reference are non-trivial we must use a
multi-pass translator (c.f. 8.1.1). However, most modern
languages permit forward references only in very simple circumstances,
so we create a dummy entry to be overwritten by the real declaration later.
The dummy entry may point to places where the identifier is used, so
e.g. generated code can be corrected.
- At the end of each scope
SPMquot "
- Check all forward references satisfied.
Some languages require us to move unsatisfied references into the enclosing
scope, if one exists, but for most this is simply an error.
- Delete all properties that are no longer relevant.
- We may need to keep some properties and/or names
e.g. public identifiers of an Abstract Data Type,
or if we use a function's parameters to hold its signature.
- We may need to copy some information for run-time debugging.
- We may also remove names that no longer have any associated properties
to speed up searches.
Some information will be used by most or all declaration kinds:
- kind
- variable/constant/function/type/etc.
- scope
 property entry of the owning function or block,
property entry of the owning function or block,
and/or the depth of nested scopes- type
- (see below)
- name in name-list
- any previous declarations of the same name in the
dictionary
- next declaration in the same scope
- (?)
Other information will be different for each declaration kind:
- constant
- For manifest constants, we determine the value at compile time and place
that value in the property entry. Otherwise, we treat it as a read-only
variable initialised at run-time.
- variable
- To plant code, we need the run-time address, usually held as (data frame,
offset in frame). The data frame is often a stack frame, but could be a global
variable frame.
A stack frame can be described by the scope information.
The offset is copied from the current size of the data frame, which we then
increment by the size of the variable, derived from the type information.
We may need extra information for other semantic rules, such as not
modifying a loop control variable inside the loop.
- parameter
- The information held is similar to that for a variable.
If the language has more than one parameter mechanism
(c.f. 12.2), or there are constraints on e.g. modifying
a value parameter, we must note how this applies to each parameter.
- record/struct fields
- Also very similar to variables, but the data frame refers to the owning
record. We calculate the offsets for fields of unions (and the total size of
the union frame) slightly differently.
We must save extra information about fields of discriminated unions, to
check if accesses are legal.
- labels
- Consist just of the code address, although we usually need to cope with
forward references as described above.
- programs, subprograms and blocks
- For a function, we need its signature: we could use the type information for
the result, and a link to the list of parameters for the rest of the
signature. However, this is not sensible if a function signature can be used
as a type. We also need the size of the stack frame. We may want to point to
a list of all properties defined within the scope to make processing
easier. Finally, we need the code address as for labels.
An entry for a procedure would be just like that for a function, but with a
null result type.
A program entry is usually needed to provide a scope for global
declarations, and to hold any language-specific information.
We do not need entries for blocks if
they are simply compound statements, but if they have associated scope or
extent rules they may need entries like those for functions, but without
signature or code address (and usually without an associated name!)
- types
- The only types some languages have are a few built-in primitive types and
vectors, and we need only remember this information and the resulting size
(e.g. in bytes) as part of the property entry for the variable, parameter or
constant.
Most modern languages allow types to be created using e.g. multi-dimensional
arrays, records, pointers or recursive types, subranges, sets, functions,
abstract data types (c.f. 15, 16,
18). If the language forces a complex declaration to be
broken up into several simpler declarations, then we can place each
declaration in a single property entry. However, most languages permit
individual declarations to be arbitrarily complex, and the implementor must
split each declaration up, creating entries as if for a whole series of
(anonymous) type declarations as well as the declaration of the named type
or variable or whatever.
Example of equivalent anonymous and explicit type declarations in C:
char (*(*x())[])() { . . . }
typedef char anon1();
typedef anon1 *anon2;
typedef anon2 anon3[];
typedef anon3 *anon4;
anon4 x() { . . . }
and possible dictionary entries (many details omitted):
| namelist |
properties |
| |
|
| char |
 |
| |
|
| anon1 |
 |
| |
|
| anon2 |
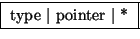 |
| |
|
| anon3 |
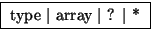 |
| |
|
| anon4 |
|
| |
|
| x |
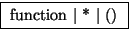 |
All languages include words that could be mistaken for identifiers, but are
actually defined as part of the language. These include words used to
describe data and control structures, typenames, conversions, values,
input/output, operators, and maths functions.
These words are treated in two main ways:
Keywords (reserved words) are built into the grammar, and so cannot
have their meaning changed by the user.
Predefined identifiers are otherwise normal identifiers, that behave
as if they were declared before the start of each program. Their meanings can
therefore be changed just like any other name, although this is rarely
sensible. These extra declarations can be handled simply by pre-inserting the
identifiers into the dictionary.
Keywords are easy to recognise by using a different LEX grammar
rule for each, but this tends to make the resulting analyser very large (and
slow for LEX to generate). Therefore, some analysers initially do
not distinguish between keywords and identifiers, but then search a special
dictionary to recognise keywords before treating everything else as an
identifier. This makes the analyser smaller but slower.
Binding
The binding of static to dynamic objects can be eager (i.e. as soon as
possible) or lazy (i.e. as late as possible).
Most high-level languages, intended for compilation, assume eager binding,
although some languages allow for constants and/or arrays whose value or
size cannot be calculated at compile time, or allow the binding of external
library functions to be delayed.
Many interpreted languages, such as shells, assume lazy binding, so we may
not even know if a variable or function exists until it is used at run-time,
let alone what type it might be.
Eager binding allows for more checking to be done once and for all, and for
faster run-times. Lazy binding allows for more feedback to the user, and may
be helpful during interactive debugging.
The description of dictionaries above assumes we are using eager binding;
lazy binding essentially requires us to move some use of the dictionary to
run-time.
( indicates harder problems)
indicates harder problems)
- Some languages treat upper-case and lower-case names as distinct
(e.g. Pascal), some as being the same (e.g. Ada), and some only allow one
case. How would you recognise and match names in an Ada compiler?
Some languages ignore characters in names past some limit. e.g. in ANSI C,
only the first 6 characters of extern identifiers have to be checked
(although more can be) and their case can be ignored. How could you use
LEX and YACC to check ANSI C programs for identifiers that
might be confused by a compiler/linker that only provided the minimum
facilities? How could you use #define to avoid any problems thus detected?
- List all the data structures you can think of that could possibly be
used for a namelist - which of them would you prefer to use and why? Can you
imagine any circumstances in which you would pick a different one?
- What identifiers do LEX and YACC (i.e. the parser
generators themselves, not the parsers they generate) each have to deal
with, and so what do they need in the way of dictionaries?
What about other Unix tools that you are familiar with, like bash?
- Check your favourite compilers to see what happens if you misspell an
identifier. Do you get just one error message? If you repeatedly misspell it
in the same way, are the error messages repeated?
- Write a set of C declarations that uses all the different kinds of
declarations, and all the sorts of types, that you can think of, and then
give the corresponding dictionary entries.
- How would you change the semantics of C to simplify semantic
analysis? What useful features of the language would be lost by this
simplification?
Louden: chs. 4.7, 5.3, 6.6
Capon & Jinks: chs. 3.3, 7.3, 9
Aho, Sethi & Ullman: chs. 2.7, 6.1-6.6, 7.6
Next: Building a Compiler: recognising
Up: CS2111: Design and Implementation
Previous: Abstract Data-Types, Modules, Classes
Contents
Pete Jinks
1999-09-30