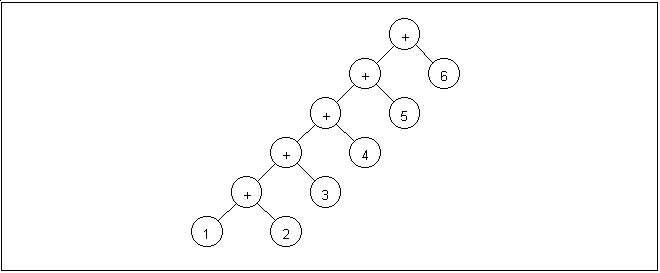
Figure 2. Parse tree for expression 1+2+3+4+5+6
Return to first page of the Compiler Theory article
The job of the parser is to detect syntax errors and build a parse tree.
Given our EBNF grammar for expressions:
S :== EXPRESSION
EXPRESSION :== TERM | TERM { [+,-] TERM] }
TERM :== FACTOR | FACTOR { [*,/] FACTOR] }
FACTOR :== number | '(' EXPRESSION ')'
And the tokenizer shown in the last section, it is now a simple matter to encode this grammar in a parser. Note that we changed the formal definition of number. The tokenizer can recognize a number, so we do not need to develop the definition any further.
The first step is to define the data structures needed for our parse tree.
TYPE exp_type_enum = (exp_add, exp_sub, exp_mul, exp_div); expression_type_ptr = ^expression_type; expression_type = record exp_type : expr_type_enum; value : real; left_expr : expression_type_ptr; right_expr : expression_type_ptr; single_expr : expression_type_ptr; end;
Strictly speaking, this structure is incorrect. According to the grammar, we should have pointers to terms coming from expressions, and from terms we should have pointers to factors, and from factors we should have a pointer to a number, and possibly back to expressions. If we followed this line of thinking we would also need a pointer to a next expression to handle the [+ term] case in the grammar. In an object oriented language creating such a complex structure can be handled easily by creating subclasses of the expression class. In Pascal the best way to handle this might be to use a variant record, but that makes for messy code in the code generator. The real reason the grammar has such convoluted structures is to make sure operator precedence is correct. We can accomplish the same goal with the shape of the parse tree, so we use this simpler data structure.
The next step is to encode the grammar rules into a set of procedure calls. This is quite a mechanical process. The expression parsing procedure looks like this:
procedure parse_expression (var exp expression_type
var token token_type);
var
temp_node : expression_type_ptr;
begin
parse_term (exp, token);
advance_token (token);
while (token.type_of_token = res_sym and
((res_sym = sym_add) or
res_sym = sym_subtract))) do
begin
new (temp_node);
if (token.type_of_token = sym_add) then
^temp_node.exp_type := exp_add
else
^temp_node.exp_type := exp_sub;
^temp_node.left_expr := exp;
exp := temp_node;
advance_token(token);
parse_term(exp.right_expr, token);
end; { while (token.type_of_token = res_sym and
((res_sym = sym_add) or
res_sym = sym_subtract))) }
end; { procedure parse_expression }
Parse_expression encodes the one rule in our grammar for parsing expressions. Since all three parts of the rule start with a term, the function makes a call to parse_term. For the first part of the rule that is the only expansion. After parsing the term we need to advance the token. The second part of the rule says we can have an arbitrary number of additions and subtractions, each one being followed by another term. So we enter a while loop. This must be a while loop because if we are expanding the first half of the rule we need to by-pass the loop.
Within the loop we allocate a new expression and set the expression's type. We then copy the previously parsed term into the left side of the new expression, and copy the new expression into the old. Now we advance the token again and parse the next term. Given the expression 1 + 2 + 3 + 4 + 5 + 6, this procedure will build a parse tree that looks like the one in figure two. Since we want the expression evaluated from left to right when we see a series of operators with the same precedence, and an in order traversal will perform the lowest operations first, this tree is what we want.
Figure 2. Parse tree for expression 1+2+3+4+5+6
Since the rule for parse_term is almost identical to parse_expression, the code is almost identical also:
procedure parse_term (var exp expression_type
var token token_type);
var
temp_node : expression_type_ptr;
begin
parse_factor (exp, token);
advance_token (token);
while (token.type_of_token = res_sym and
((res_sym = sym_multiply) or
res_sym = sym_divide))) do
begin
new (temp_node);
if (token.type_of_token = sym_multiply) then
^temp_node.exp_type := exp_mult;
else
^temp_node.exp_type := exp_div;
^temp_node.left_expr := exp;
exp := temp_node;
advance_token(token);
parse_factor(exp.right_expr, token);
end; { while (token.type_of_token = res_sym and
((res_sym = sym_add) or
res_sym = sym_subtract))) }
end; { procedure parse_term }
The code for parse factor is just a little bit different:
procedure parse_factor (var exp expression_type
var token token_type);
begin
if (token.token_type = int_type ) or
(token.token_type = real_type) then
begin
new (exp);
^exp.exp_type := exp_const_value;
if (token.token_type = real_type) then
exp.value := token.float_val
else
exp.value := token.int_val;
return;
end; if (token.token_type = int_type ) or
(token.token_type = real_type)
if (token.token_type = reserved_sym) and
(token.res_sym = open_paren) then
begin
advance_token(token);
parse_expression (exp, token);
if (token.token_type = reserved_sym) and
(token.res_sym = close_paren) then
advance_token(token)
return;
else
(* this is an error - missing closing paren *)
raise_error;
end;
(* if we got here, then there was an illegal element in *)
(* expression. Raise an error *)
raise_error;
end; { procedure parse_factor }
According to our grammar a factor is either a number or a parenthised expression. So we look first for a number. Our tokenizer deals with two types of numbers, where our grammar only recognizes one, so we test the token for either type of number. If the token is a number we allocate the expression and put the number into it. Otherwise we look for a parenthised expression. If the token is an opening parenthesis, we advance the token to consume the parenthesis and call parse_expression. On the return of that call there should be a closing parenthesis. If there is we again call advance_token, otherwise we raise an error. Note that we could create an expression type for parentheses, and place a node in our parse tree to represent the parentheses we've found. For a simple calculator program, or a compiler that generates low level code, we do not need to do that. The shape of the parse tree determines precedence, so putting the parentheses in is redundant. If you are writing a compiler that compiles from one high level language to another, that is a different story. In that case you will end up writing out expressions in standard notation, and parentheses are needed to set precedence.
With the little code shown here we can handle surprisingly complex expressions. An expression like 1 + 2 * 3 + 4 * 5 will be represented accurately, as will 1 + 2 * (3 + 4) * 5 (figure 3).
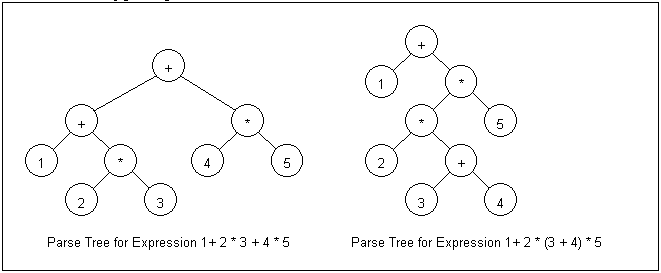
Figure 3. Parse Trees Develop from the Example Code
Notice that the parenthised sub-expression appears at the bottom of the parse tree. This indicates highest precedence or tightest binding. The two appears lower in the tree than the five, indicating left to right evaluation.
We built this parser using an EBNF grammer. Now lets take another look at the CNF grammar:
S -> EXPRESSION EXPRESSION -> TERM | TERM + EXPRESSION | TERM - EXPRESSION TERM -> FACTOR | FACTOR * EXPRESSION | FACTOR / EXPRESSION FACTOR -> number | ( EXPRESSION )
Again, this can be directly and mechanically translated to computer code. But in this case the code will be more highly recursive. Here is the code for parse_expression:
procedure parse_expression (var exp expression_type
var token token_type);
var
temp_node : expression_type_ptr;
begin
parse_term (exp, token);
advance_token (token);
if (token.type_of_token = res_sym and
((res_sym = sym_add) or
res_sym = sym_subtract))) then
begin
new (temp_node);
if (token.type_of_token = sym_add) then
^temp_node.exp_type := exp_add
else
^temp_node.exp_type := exp_sub;
^temp_node.left_expr := exp;
exp := temp_node;
advance_token(token);
parse_expression(exp.right_expr, token);
end; { if (token.type_of_token = res_sym and
((res_sym = sym_add) or
res_sym = sym_subtract))) }
end; { procedure parse_expression }
This function now must make a recursive call, rather than using a while loop. Now we can take a more detailed look at a left recursive grammer, and see why it will not work. Here is the grammer:
S -> EXPRESSION
EXPRESSION -> TERM | EXPRESSION + TERM | EXPRESSION - TERM
TERM -> FACTOR | FACTOR * EXPRESSION | FACTOR / EXPRESSION
FACTOR -> number | ( EXPRESSION )
And here is parse_expression for this grammer:
procedure parse_expression (var exp expression_type
var token token_type);
var
temp_node : expression_type_ptr;
begin
parse_expression (exp, token);
advance_token (token);
if (token.type_of_token = res_sym and
((res_sym = sym_add) or
res_sym = sym_subtract))) then
begin
new (temp_node);
if (token.type_of_token = sym_add) then
^temp_node.exp_type := exp_add
else
^temp_node.exp_type := exp_sub;
^temp_node.left_expr := exp;
exp := temp_node;
advance_token(token);
parse_term(exp.right_expr, token);
end; { if (token.type_of_token = res_sym and
((res_sym = sym_add) or
res_sym = sym_subtract))) }
end; { procedure parse_expression }
We can now see how this will enter an infinite loop. The first thing the procedure does is calls itself without first advancing the token. If we did advance the token first, we'd miss tokens, but if we do not, parse_expression simply keeps calling itself in an infinite loop.
Since an EBNF or CNF grammar can be mechanically converted into parse code it seems that it should be possible to write a computer program to do this for us. That is exactly what the program YACC (Yet Another Compiler Compiler) does. (I wanted to provide a link here to a page with a good YACC explanation. The best I've found is the SunOS YACC man page, but I did find an excellent page on BISON, the GNU version of YACC.)
The mechanics of parsing expressions is the most difficult part of parsing. Once you understand that, emphasis switches from the mechanics of parsing to storing what we parsed. In order to save space here example code and EBNF grammars will not be given.
In Pascal there are three types of data that need to be parsed and stored separately. These types are identified with the key words CONST, TYPE and VAR. In this paper we will not worry about const data.
Type data is used as a mask for declaring variables with a certain structure. Type definitions can be one of the following:
We will not deal with variant records, sets or labels at this time. Records can contain nested records.
The ideal method of storing type data is with variant records. Pascal's variant record facility is rather ugly, so we will avoid its use. (C's union facility is a much cleaner implementation of the variant record concept. When implementing a compiler in C, I would use unions.)
In order to hold enumerations, we should first take a close look to make sure we understand what an enumeration is. When the enumerated type is first declared the compiler assigns each enumeration an integer value. Then during compilation the enumerations are exchanged for their integer values. For example, given the enumeration
exp_type_enum = (exp_add, exp_sub, exp_mul, exp_div);
The enumeration exp_add receives a value of 1, exp_sub a value of 2, etc. During compilation, whenever exp_add is encountered, the value 1 is substituted. So when the code
if (parse_tree_node.node_type = exp_add) then
is seen by compiler, it substitutes
if (parse_tree_node.node_type = 1) then
If parse_tree_node.node_type holds a value of exp_mul, then we will end up comparing 3 with 1, and the if statement will be bypassed. This conversion to integers makes for object code that is quite efficient.
To hold an enumerated type we need a linked list of strings, each string holding an enumeration. This is another example of where C can lead to a cleaner, more efficient implementation. In C we can count the number of values in the enumeration, and allocate an array of strings. The index for an enumerated value in the array is the integer that the compiler will assign to the value. The same concept can be applied to Pascal, where the position in an ordered linked list will give the integer value. This can be inefficient in terms of finding the item and assigning values when compiling. If the time needed to search is a concern, the enumerations can be stored in a binary search tree, along with their assigned value, but this takes more storage.
type
enum_value_ptr = ^enum_values;
enum_values = record
program_value : array [1..30] of char;
next : enum_value_ptr;
end; {record}
Next we will deal with records. This is the most challenging aspect of storing type definitions. A record may contain any number of fields, each field being either an intrinsic type (int, real, char, boolean) or a declared type (record, array, enumeration, pointer). So we need a linked list with one element for each field in the record. The nodes in the list need to contain the name of the field, its type if it is an intrinsic type, or a pointer to the type declaration if it is a declared type.
type_decl_ptr = ^type_declaration_record;
decl_type_enum = (int_type, real_type, char_type, bool_type,
rec_type, array_type, enum_type, ptr_type);
field_ptr = ^field_decl;
field_decl = record
decl_type : decl_type_enum;
declared_type : type_decl_ptr;
next_field : field_ptr;
end; {record}
Things are getting a little more complex. Type_decl_ptr points to types declared by the programmer. We are not yet ready to develop the full definition of this record, but we need a pointer to this type now. The field decl_type in field_decl holds the type of the field. Declared_type is only used if decl_type is rec_type or array_type. Things might be more readable if a boolean field user_declared_type were added to the record, but this is not necessary for the compiler to operate. The declared_type pointer will be used by the code generator to allocate space for nested user declared types. The code generator will need to know how many bytes to allocate for the record as a whole, and to do that it needs to find its way from the parent record to the type fields declared inside. The next_field is for storing a list of fields in a record declaration.
An alternate method to using a pointer is to store a string containing the nested type's name. At some point the type will need to be looked up in the type declarations table. If we store a pointer, that lookup must be done when the record declaration is parsed. If we store a string we must perform the lookup every time that particular field of the parent record is accessed in the code, and again when code is generated. So storing the pointer leads to faster compile times and less memory used.
An array can store any type used by Pascal, so we need fields to store the beginning array index, the ending index, and we a type_decl_ptr.
array_ptr = ^array_decl_record;
array_decl_record = record
start_indx,
end_ind : integer;
array_type : type_decl_ptr;
end; {record}
A pointer can be pointed at any of the above types. To mark a pointer, we need a boolean field in the type_declaration_record, and a place to store the name of the target type. When we come across a pointer type declaration, we store the name and mark the pointer field as true. When the type the pointer is pointing to is found the rest of the information can be filled in.
And finally, we need a single record type that holds pointers to all the possible types. Such a record can be defined as:
type_declaration_record = record
decl_name : array [1..30] of char;
decl_type : decl_type_enum;
pointer_to : boolean;
pointer_target_type : array [1..30] of char;
enum_values_list : enum_value_ptr;
field_decl_list : field_ptr;
array_decl : array_ptr;
end; {record}
As variables are parsed there will be a constant need to look up type declarations in the type declaration tables. It is a good idea to store such declarations as binary search trees.
type_decl_table_rcd_ptr = ^type_declarations_table_record;
type_declarations_table_record = record
declaration : type_decl_ptr;
left,
right : type_decl_table_rcd_ptr;
end; {record}
==================================================================
Parsing variable declarations is fairly simple compared to parsing type definitions. The name of the variable is read, then the type. If the type is a user declared type, a pointer is pointed to the definition of the type. Pascal allows a record or array to be defined as part of a variable declaration. In this case the definition needs to be stored, using the structures shown above. Note that these should not be placed into the type declarations table, because the declaration is only available to the one variable. The following data structures allow for variable declarations:
Var_Decl = ^var_decl_record;
Var_Decl_Record = record
Name : char [1..30];
var_type : type_decl_ptr;
end; {record}
Again, we will need to look up individual variables time and again during parsing. In order facilitate finding variables quickly, they should be stored in tables implemented as binary search trees.
The data structures presented here are not quite adequate for a code generator. The code generator will use the declarations to set aside memory, then set variable references in the code to point to the correct address. At some point the address of each variable will need to be calculated by determining the size of all variables. These addresses should then be stored with the variable declaration so the code generator can reference them. Calculating addresses should be the job of the code generator, but we need to plan ahead for it now, and make room for these addresses.
These data structures are not adequate for an interpreter, either. An interpreter needs to allocate space for variables as it parses, so that data can actually be stored. Consider what this means for record variables.
Go to next page of Compiler Theory article
Return to start of this page
Return to Table of Contents of the Compiler Theory article
Return to High Tech page