Compiler-Supported Simulation of Highly Scalable Parallel Applications
Vikram S. Adve1 Rajive Bagrodia2 Ewa Deelman2 Thomas Phan2 Rizos Sakellariou3
1 University of Illinois at Urbana-Champaign
2 University of California at Los Angeles 3Rice University
Abstract
In this paper, we propose and evaluate practical, automatic techniques that exploit compiler analysis to facilitate simulation of very large message-passing systems. We use a compiler-synthesized static task graph model to identify the control-flow and the subset of the computations that determinees the parallelism, communication and synchronization structure of the code, and to provides generate symbolic estimates of sequential task execution times. This information allows us to avoid executing or simulating large portions of the computational code during the simulation. We are using have used these techniques in to integrateting the MPI-Sim parallel simulator at UCLA with the Rice dHPF compiler infrastructure,. to The integrated system enable us to can simulate unmodified High Performance Fortran (HPF) programs compiled to the Message-Passing Interface standard (MPI) by the dHPF compiler, and we expect to simulate MPI programs as well. We evaluate the accuracy and benefits of these techniques for three standard benchmarks on a wide range of problem and system sizes. unmodified MPI and HPF programs without any user intervention. We Our results show that the optimized simulator has errors of less than 17% compared with direct program measurement in all the cases we studied, and typically much smaller errors. Furthermore, it requires 2 to 3 orders of magnitude factors of 5 to 2000 less memory and up to a factors of 5 -10 times less time to execute than the original simulator. These dramatic savings allow us to simulate systems and problem sizes 10 to 100 times larger than is possible with the original simulator.
Performance Ppredicting parallel application performance ion of is an essential step in developing large applications on highly scalable parallel architectures, in sizing the system configurations necessary for large problem sizes, or in analyzing alternative architectures for such systems. is commonly used by application developers to size system configurations that may be necessary for large problem sizes, and by system designers for analysis of alternative designs. Because aAnalytical intractability performance prediction can be intractable for of complex applications, has led to the use of program simulations as a are commonly used technique for such studies. It is well known that simulations of large systems tend to be slow. ; Ttwo techniques have been used to alleviate the problem of long execution times: direct execution of sequential code blocks [6667, , 11, 141112, 17171718, 15151518181819] and parallel execution of the simulation models using parallel simulation algorithms [8889, 13131315151516, 15
*]. Although these techniques have reduced simulation times, the resulting improvements are still inadequate to efficiently simulate the very large problems that are of interest to high-end users. For instance, Sweep3D is a kernel application of the ASCI benchmark suite released by the US Department of Energy. In its largest configuration, it requires computations on a grid with one billion elements. The memory requirements and execution time of such a model configuration makes it impractical to simulate, even when running experiments the simulations onusing high performance computers with hundreds of processors.To overcome this computational intractability, researchers have used abstract simulations, which avoid execution of the computational code entirely [99910, 10101011]. However, this leads to major limitations that make the approach inapplicable to many real world applications. The main problem with abstracting away all of the code is that the model is essentially independent of the program control flow, in a program that even though the control flow may affect both the communication pattern as well as the sequential task times. Also, the preceding solutions requires significant user modifications to the source program (in the form of a special input language) in order to express required information about abstracted sequential tasks and communication patterns. This makes it difficult to apply such a tool s to existing programs written with widely used standards such as Message Passing Interface (MPI) or High Performance Fortran (HPF).
In this paper, we propose and evaluate practical, automatic techniques to exploit compiler support for simulation of very large message-passing parallel programs. Our goal is to enable the simulation of target systems with thousands of processors, and realistic problem sizes expected on such large platforms. The key idea underlying our work is to use compiler analysis to derive abstract performance models for parts of the application. These models enable the simulator to accurately predict the performance of these program fragments without executing the corresponding code. We use the compiler-synthesized static task graph model for this purpose [2, 3]. This is an abstract representation that clearly identifies the sequential computations (tasks), the parallel structure of the program (task scheduling, precedences, and explicit communication), and the control-flow that determines the parallel structure [2]. In order to ensure that control flow is not ignored, we use the a compiler technique known as program slicing [12121213131314141415] compiler technique to isolate the portions of the computation that affect intermediate values the parallel structure of the program and directly execute thesese corresponding computations during the simulation. This allows us to capture the exact effect of these values computations on program behaviorperformance, while abstracting away the remaining code. We also approximate the execution times of the abstracted sequential tasks by using symbolic expressions. The estimates we currently use are fairly simple, and are parameterized by direct measurement. Refining these values and developing analytical approximation techniques less dependent on measurement are an important component of our ongoing work.
We are have combinednintegrat ing the MPI-Sim parallel simulator [5, 6, 14141417171718] with the dHPF compiler infrastructure [1], incorporating the new techniques described above. The original MPI-Sim uses both direct execution and parallel simulation to significantly reduce the simulation time of parallel programs. dHPF, in normal usage, compiles an HPF program to MPI (or to a variety of shared memory systems), and provides extensive parallel program analysis capabilities. The integrated tool can will allow us to perform simulation for MPI and MPI and HPF programs without requiring any changes to the source code. . In normal usage, dHPF compiles an HPF program to MPI, or to a variety of shared memory systems. We In previous work, we have modified the dHPF compiler to automatically synthesize the static task graph model and symbolic task time estimates for MPI programs compiled from HPF source programs. In this work, we use the static task graph to perform the simulation optimizations described above. In order to communicate the information in the static task graph to MPI-Sim, Wwe are have extendeding the compiler to emit simplified MPI code that captures the required information from the static task graph (STG) and contains exactly the computation and communication code that must be actually executed during simulation. (This is described in more detail in Section 3). MPI-Sim uses both direct execution and parallel simulation to dramatically reduce the simulation time of parallel programs.programs [6]. In this work, Wwe have also extended MPI-Sim to exploit the compiler-synthesized static task graph model to estimateand the sequential task time estimates, s and avoid executing significant portions of the computational code. The hypothesis is that this will significantly reduce the memory and time requirements of the simulation and therefore enable us to simulate much larger systems and problem sizes than were previously possible.
The applications used in this paper include Sweep3D [16161619191920202021], a key ASCI benchmark; SP from the NPB benchmark suite [4445] and Tomcatv, a SPEC92 benchmark. The simulation models of each application were validated against measurements for a wide range of problem sizes and numbers of processors, where such measurements were feasible. The error in the predicted execution times, compared with direct measurement, was were found to be at most 17% in all cases we studied, and often substantially less. The validations have been done for the distributed memory IBM SP as well as the shared memory SGI Origin 2000 (note, that MPI-Simthe simulator simulates the MPI communication, not the communications via shared memory). Furthermore, the total memory usage of the simulator using the compiler synthesized model is 2-3 orders of magnitude is factors of 5 to 2000 less than the original simulator, and the simulation time is typically 5-10 times less. These dramatic savings allow us to simulate systems or problem sizes that are 1-2 orders of magnitude larger than is possible with the direct execution based original simulator. For example, In particular, wewe were successful in simulating the execution of a configuration of Sweep3D for a target system with 10,000 processors! In another casemany cases, the execution simulation time of a model of the Tomcatv application was 100 times was faster than the original program that was being simulated, even though the communication was simulated in detail.
The remainder of the paper proceeds as follows. Sections 112 2 and 3 provides a brief overview of MPI-Sim and , the static task graph model, and describes our goals and overall strategy. Section 3 describes the process of integrating the twodHPF and MPI-Sim. Section 4 describes the our experimental results, and Section 5 presents our main conclusionsdes the paper.
The starting point for our work is MPI-Sim, a direct-execution parallel simulator for performance prediction of MPI programs. MPI-Sim simulates an MPI application running on a parallel system (referred to as the target program and system respectively). The machine on which the simulator is executed (the host machine) may be either a sequential or a parallel machine. In general, the number of processors in the host machine will be less than the number of processors in the target architecture being simulated, so the simulator must support multi-threading. The simulation kernel on each processor schedules the threads and ensures that events on host processors are executed in their correct timestamp order. A target thread is simulated as follows. The local code is simulated by directly executing it on the host processor. Communication commands are trapped by the simulator, which uses an appropriate model to predict the execution time for the corresponding communication activity on the target architecture.
The simulation kernel provides support for sequential and parallel execution of the simulator. Parallel execution is supported via a set of conservative parallel simulation protocols [6] and has been shown to be effective in reducing the execution time of the simulation models [5]. However, the use of direct execution in the simulator implies that the memory and computation requirements of the simulator are at least as large as that of the target application, which restricts the target systems and application problem sizes that can be studied even using parallel host machines. The compiler-directed optimizations discussed in the next section are primarily aimed at alleviating these restrictions.
Parallel program simulators used for performance evaluation execute or simulate the actual computations of the target program for two purposes: (a) to determine the execution time of the computations, and (b) to determine the impact of computational results on the performance of the program, due to artifacts like communication patterns, loop bounds, and control-flow. For many parallel programs, however, a sophisticated compiler can extract extensive information from the target program statically. In particular, we identify two types of relevant information often available at compile-time:
If this information can be provided to the simulator directly, it may be possible to avoid executing substantial portions of the computational code during simulation, and therefore reduce the execution time and memory requirements of the simulation.
To illustrate this goal, consider the simple example MPI code fragment in Figure 1. The code performs a "shift" communication operation on the array D, where every processor sends its boundary values to its left neighbor, and then the code executes a simple computational loop nest. In this simple example, the communication pattern and
The starting point for our work is MPI-Sim, a direct-execution parallel simulator for performance prediction of MPI programs. MPI-Sim simulates an MPI application running on a parallel system (referred to as the target program and system respectively). The machine on which the simulator is executed (the host machine) may be either a sequential or a parallel machine. In general, the number of processors in the host machine will be less than the number of processors in the target architecture being simulated, so the simulator must support multi-threading. The simulation kernel on each processor schedules the threads and ensures that events on host processors are executed in their correct timestamp order. A target thread is simulated as follows. The local code is simulated by directly executing it on the host processor. Communication commands are trapped by the simulator, which uses an appropriate model to predict the execution time for the corresponding communication activity on the target architecture.
The simulation kernel provides support for sequential and parallel execution of the simulator. Parallel execution is supported via a set of conservative parallel simulation protocols [7] and has been shown to be effective in reducing the execution time of the simulation models [6]. However, the use of direct execution in the simulator implies that the memory and computation requirements of the simulator are at least as large as that of the target application, which restricts the target systems and application problem sizes that can be studied even using parallel host machines. The compiler-directed optimizations discussed in the next section are primarily aimed at alleviating these restrictions.
Parallel program simulators used for performance evaluation execute or simulate the actual computations of the target program for two purposes: (a) to determine the execution time of the computations, and (b) to determine the impact of computational results on the performance of the program, due to artifacts like communication patterns, loop bounds, and control-flow. For many parallel programs, however, a sophisticated compiler can extract extensive information from the target program statically. In particular, we identify two types of relevant information often available at compile-time:
If this information can be provided to the simulator directly, it may be possible to avoid executing substantial portions of the computational code during simulation, and therefore reduce the execution time and memory requirements of the simulation.
To illustrate this goal, consider the simple example MPI code fragment in Figure 1. The code performs a "shift" communication operation on the array D, where every processor sends its boundary values to its left neighbor, and then the code executes a simple computational loop nest. In this simple example, the communication pattern and the number of iterations of the loop nest depend on the values of the block size per processor (b), the array size (N), the number of processors (P), and the local processor identifier (myid). Therefore, the computation of these values must be executed or simulated during the simulation. However, the communication pattern and loop iteration countsy do not depend on the values stored in the arrays A and D, which are computed and used in the computational loop nest (or earlier). Therefore, if we can estimate the performance of the computational loop nest analytically, we could avoid simulating the code of this loop nest, while still simulating the communication behavior in detail. We could achieve this by generating the simplified code shown on the right in the figure, where we have replaced the loop nest with a call to a special simulator-provided delay function. We have extended MPI-Sim to provide a special delay such a function that which simply forwards the simulation clock on the simulation threadlocal process by a specified amount. The compiler estimates the cost of the loop nest in the form of a simple scaling function shown as the argument to the delay call. This function describes how the computational cost varies with the retained variables (b, N, P and myid), plus a parameter wloop w1 representing the cost of a single loop iteration. We currently obtain the value of wloop w1 by direct measurement for a singleone or a few selected problem sizes and/or number of processors, and use the scaling function to compute the required delay value for other problem sizes or and number of processors.
As part of the POEMS project [7778], we have developed an abstract program representation called the static task graph (STG) that captures extensive static information about a parallel program, including all the information mentioned above. The STG is designed to be computed automatically by a parallelizing compiler.; in particular, Iit is a compact, symbolic representation of the parallel structure of a program, independent of specific program input values or the number of processors. Each node of the STG represents a set of possible parallel tasks, typically one per process, identified by a symbolic set of integer process identifiers as illustrated below. To illustrate, the STG for the example MPI program is shown in Figure 1. The compute node for the loop nest represents a set of tasks, one per process, denoted by the symbolic set of process ids ![]() . Each node also includes markers describing the corresponding region of source code of the original program. (for now, each node must represent a contiguous region of code). Each edge of the graph represents a set of parallel edges connecting pairs of parallel tasks described by a symbolic integer mapping. For example, the communication edge in the figure is labeled with a mapping indicating that each process p (
. Each node also includes markers describing the corresponding region of source code of the original program. (for now, each node must represent a contiguous region of code). Each edge of the graph represents a set of parallel edges connecting pairs of parallel tasks described by a symbolic integer mapping. For example, the communication edge in the figure is labeled with a mapping indicating that each process p (![]() ) sends to process q = p-1. STG nodes fall into one of three categories: control-flow, computation and communication. Each computational node includes a symbolic scaling function that captures how the number of loop iterations in the task scales as a function of arbitrary program variables. Each communication node includes additional symbolic information describing the pattern and volume of communication. Overall, the static task graphSTG serves as a general, language- and architecture-independent representation of message-passing programs (and can be extended to shared-memory programs as well). In previous work, we extended the dHPF compiler to synthesize static (and dynamic) task graphs for MPI programs generated by the dHPF compiler from HPF source programs [3]. In the future, we will extract task graphs directly from existing MPI codes.
) sends to process q = p-1. STG nodes fall into one of three categories: control-flow, computation and communication. Each computational node includes a symbolic scaling function that captures how the number of loop iterations in the task scales as a function of arbitrary program variables. Each communication node includes additional symbolic information describing the pattern and volume of communication. Overall, the static task graphSTG serves as a general, language- and architecture-independent representation of message-passing programs (and can be extended to shared-memory programs as well). In previous work, we extended the dHPF compiler to synthesize static (and dynamic) task graphs for MPI programs generated by the dHPF compiler from HPF source programs [3]. In the future, we will extract task graphs directly from existing MPI codes.
This paper develops techniques that use the static task graph model (plus additional compiler analysis) to enhance the efficiency and scalability of parallel direct-execution simulation, and evaluates the potential benefits of these techniques. In particular, our goal is to exploit the information in the static task graph to avoid simulating or executing substantial portions of the computational code of the target program. The STG for the example MPI program is shown in Figure 1. The example graph includes computation, control-flow and communication nodes, as well as control flow and communication edges. Each node represents a set of tasks, one per process (denoted by a symbolic set of process ids such as ![]() ). Each edge represents a set of dynamic edge instances connecting pairs of tasks described by a symbolic integer mapping. For example, the communication edge in the figure is labeled with a mapping indicating that each process p (
). Each edge represents a set of dynamic edge instances connecting pairs of tasks described by a symbolic integer mapping. For example, the communication edge in the figure is labeled with a mapping indicating that each process p (![]() ) sends to process q = p-1. For more details on the STG, the reader is referred to [2, 3].
) sends to process q = p-1. For more details on the STG, the reader is referred to [2, 3].
In this work, weWe use the task graph to identify the computational tasks, decide which computational regions can be collapsed into delay functions, and compute the scaling expressions for those delay functions. In the example of Figure 1is example, we decide based on the task graph that the entire loop nest could be collapsed into a single "condensed" task and replaced with a single delay function., Tand we compute the scaling expression for this delay function as computed by the compiler is shown in part (c) of the figure. We can also use a delay function for the compute task at the top of the graph, but we need to retain the code that computes the values of N, myid, b, and P, as explained above. We use the compiler analysis described in Section 3.2 to expose this code make this decision.
This paper develops techniques that use the static task graph model (plus additional compiler analysis) to enhance the efficiency and scalability of parallel direct-execution simulation, and evaluates the potential benefits of these techniques. In particular, our goal is to exploit the information in the static task graph to avoid simulating or executing substantial portions of the computational code of the target program. There are three major challenges we must address in achieving this the above goal, of which the first two have not been addressed in any previous system known to us:
The next section describes the techniques we use to address these challenges, and their implementation in dHPF and MPI-Sim. Section 4 describes our evaluation of the benefits of these techniques.
OAs described above, our overall goal is to translate a given MPI program into a simplified, complete MPI program that can then be directly input to MPI-SIM. The static task graph serves as the parallel program representation that we use to perform this translation. In previous work, we extended the dHPF compiler to synthesize static (and dynamic) task graphs for MPI programs synthesized by the dHPF compiler from HPF source programs [3]. In the future, we will extract task graphs directly from existing MPI codesprograms. We first describe the basic process of using the task graph to generate the simplified MPI program, then describe the compiler analysis needed to retain portions of the computational code and data, and finally discuss the approach we usees to estimate ing the performance of the eliminated code.
The STG directly identifies the local (sequential) computational tasks, control flow, and communication tasks and patterns of the parallel program. The next stage is to identify contiguous regions of computational tasks and /or control-flow in the STG that can be collapsed into a single condensed (or collapsed) task, such as the loop nest of Figure 1. Note that this is simply a transformation of the STG for simplifying further analysis and does not directly imply any changes to the parallel program itself. We refer to the task graph resulting from this transformation as the condensed task graph. In later analysis, we can consider only a single computational task or a single collapsed task at a time for deciding how to simplify the code (we refer to either as a single sequential task).
The criteria for collapsing tasks depend on the goals of the performance study. First, as a general rule, a collapsed region must not include any branches that exit the region, i.e., there should be only a single exit at the end of the region. Second, for the current work, a collapsed region must contain no communication tasks because we aim to simulate communication precisely. Finally, deciding whether to collapse conditional branches involves a difficult tradeoff: it is important to eliminate control-flow that references large arrays in order to achieve the savings in memory and time we desire, but it is difficult to estimate the performance of code containing such control-flow. We have found, however, that there are typically few branches that involve large arrays that do have a significant impact on program performance. For example, one minor conditional branch in a loop nest of Sweep3D depends on intermediate values of large 3D arrays. The impact of this branch on execution time is relatively negligible unimportant, but detecting this fact in general can be difficult within the compiler because it may depend on expected problem sizes and computation times. Therefore, there are two possible approaches we can take. The more precise approach is to allow the user to specify through directives that specific branches can be eliminated and treated analytically for program simulation. A simpler but more approximate approach is to eliminate any conditional branches inside a collapsible loop nest, and rely on the statistical average execution time of each iteration to provide a good basis for estimating total execution time of the loop nest. With either approach, we can use profiling to estimate the branching probabilities of eliminated branches We have currently taken the second approach, but the first one is not difficult to implement and will becould provide more precise performance estimates.
While collapsing the task graph, we also compute a scaling expression for each collapsed task that describes how the number of computational operations scales as a function of program variables. We introduce time variables that represent the execution time of a sequence of statements in a single loop iteration (denoted wi for task i). The approach we use to estimate the overall execution time of each sequential task is described in Section 3.3.
Based on the condensed task graph (and assuming for now that the compiler analysis of Section 3.2 is not needed), we generate the simplified MPI program as follows. We retain any control-flow (loops and branches) of the original MPI code that is retained in the condensed task graph, i.e., the control-flow that is external to the condensed tasksnot collapsed. Second, we retain the communication code of the original program, in particular only the calls to the underlying message-passing library. If a program array that is otherwise unused is referenced in any communication call, we replace that array reference with a reference to a single dummy buffer used for all the communication. We use a buffer size that is the maximum of the message sizes of all communication calls in the program and allocate the buffer statically or dynamically (potentially multiple times), depending on when the required message sizes are known. Third, we replace the code sequence for each sequential task of the task graph by a call to the MPI-Sim delay function, and pass in an argument describing the execution time of the task. We insert a sequence of calls to a runtime function, one per wi parameter,f
A major challenge that was mentioned earlier is that intermediate computational results can affect the program execution time in a number of ways. The solution we propose is to use program slicing to retain those computational parts of the computational code (and the associated data structures) that affect the program execution time. Given a variable referenced in some statement, program slicing finds and isolates a subset of the program computation and data that determines can affect the value of that variable [12121213131314]. The subset has to be conservative, limited by the precision of static program analysis, and therefore may not be minimal.
We begin by finding the variables whose values affect relevant execution time metrics, determined by the goals and desired accuracy of the performance study. For this work, these variables are exactly the variables that appear in the retained control-flow of the condensed graph, in the scaling functions of the sequential tasks, and in the calls to the communication library. Program slicing would then isolate the computations that compute affect those variable values.
Obtaining the memory and time savings we desire requires interprocedural program slicing, so that we completely eliminate the uses of as many large arrays as possible. General interprocedural slicing is a challenging but feasible compiler technique that is not currently available in the dHPF infrastructure. For now, we take limited interprocedural side-effects into account, in order to correctly handle calls to runtime library routines (including communication calls and runtime routines of the dHPF compiler’s runtime library). In particular, we assume that these routines can modify any arguments passed by reference but cannot modify any global (i.e., common block) variables of the MPI program. This is necessary and sufficient to support single-procedure benchmarks. We expect to incorporate full interprocedural slicing in the near future, to support continuing work in POEMS.
The main approximation in our approach is to estimate sequential task execution times without direct execution. Analytical prediction of sequential execution times is an extremely challenging problem, particularly with modern superscalar processors and cache hierarchies. There are a variety of possible approaches with different tradeoffs between cost, complexity, and accuracy.
The simplest approach, and the one we use in this paper, is to measure task times (specifically, the wi) for one or a few selected problem sizes and number of processors, and then use the symbolic scaling functions derived by the compiler to estimate the delay values for other problem sizes and number of processors. Our current scaling functions are symbolic functions of the number of loop iterations, and do not incorporate any dependence of cache working sets on problem sizes. We believe extensions to the scaling function approach that capture the non-linear behavior caused by the memory hierarchy are possible.
Two alternatives to direct measurement of the task time parameters are (a) to use compiler support for estimating sequential task execution times analytically, and (b) to use separate offline simulation of sequential task execution times [7]. In both cases, the need for scaling functions remains, including the issues mentioned above, because it is important to amortize the cost estimating these parameters over many prediction experiments..
The scaling functions for the tasks can depend on intermediate computational results, in addition to program inputs. Even if this is not the case, they may appear to do so to the compiler. For example, in the NAS benchmark SP, the grid sizes for each processor are computed and stored in an array, which is then used in most loop bounds. The use of an array makes forward propagation of the symbolic expressions infeasible, and therefore completely obscures the relationship between the loop bounds and program input variables. We simply retain the executable symbolic scaling expressions, including references to such arrays, in the simplified code and evaluate them at execution time.
We have been able to automate fully the modeling process for a given HPF application compiled to MPI. The modified dHPF compiler automatically generates two versions of the MPI program. One is the simplified MPI code with delays calls described previously. The second is the full MPI code with timer calls inserted to perform the measurements of the wi parameters. The output of the timer version can be directly provided as input to the delay version of the code. This complete process is illustrated in Figure 2.
Two alternatives to direct measurement are (a) to use compiler support for estimating sequential task execution times analytically, and (b) to use separate offline simulation of sequential task execution times [8]. In both cases, the need for scaling functions remains, including the issues mentioned above.
We performed a detailed experimental evaluation of the compiler-based simulation approach. We studied three issues in these experiments:
We begin with a description of our experimental methodology and then describe the results for each of these issues in turn.
We used three real-world benchmarks (Tomcatv, Sweep3D and NAS SP) and one synthetic communication kernel (SAMPLE) in this study. Tomcatv is a SPEC92 floating-point benchmark, and we studied an HPF version of this benchmark compiled to MPI by the dHPF compiler. Sweep3D, a Department of Energy ASCI benchmark [16161619191920202021], and SP, a NAS Parallel Benchmark from the NPB2.3b2 benchmark suite [4445], are MPI benchmarks written in Fortran 77. Finally, wWe designed the synthetic kernel benchmark, SAMPLE, to evaluate the impact of the compiler-directed optimizations on programs with varying computation granularity and message communication patterns that are commonly used in parallel applications.
For Tomcatv, we use the dHPF compiler automatically generates three versions of the output MPI code: (a) the normal MPI code generated by dHPF for this benchmark, where the key arrays of the HPF code are distributed across the processors in contiguous blocks in the second dimension (i.e., using the HPF distribution
For each application, we measured the task times (values of wi) on 16 processors. These measured values were then used in experiments with the same problem size on different numbers of processors. The only exception was NAS SP, where we measured the task only for a single problem size (on 16 processors), and used the same task times for other problem sizes as well. Recall that the scaling functions we use currently do not account for cache working sets and cache performance. Changing either the problem size or the number of processors affects the working set size per process and, therefore, the cache performance of the application. Nevertheless, the above measurement approach provided very accurate predictions from the optimized simulator, as shown in the next subsection.
All benchmarks, except SAMPLE, were evaluated for the distributed memory IBM SP (with up to 128 processors);, the SAMPLE experiments were conducted on the shared memory SGI Origin 2000 (with up to 8 processors).
The original MPI-Sim was successfully validated on a number of benchmarks and architectures [5556, 6667]. The new techniques described in Section 3, however, introduce additional approximations in the modeling processIn this section our aim is to evaluate the accuracy of MPI-Sim when applying the techniques described so far. The key new approximation is in estimating the sequential execution times of portions of the computational code (tasks) that have been abstracted away. Our aim in this section is to evaluate the accuracy of MPI-Sim when applying these techniques.
For each application, tThe optimized simulator was validated against physical direct measurements of the application execution timeusing multiple configurations of the preceding applications and also compared with the predictions from the original simulator. We studied multiple configurations (problem size and number of processors) for each application.In the following results, we estimated the task times on 16 processors. These measured values were then used in experiments with the same problem size on different numbers of processors.
We begin with Tomcatv, which is handled fully automatically through the steps of compilation, task measurements, and simulation shown in Figure 2. The size of Tomcatv used for the validation was 2048´ 2048. Figure 32 shows the results from 4 to 64 processors. Even though MPI-Sim with the analytical model (MPI-SIM-AM) is not as accurate as MPI-Sim with direct execution (MPI-SIM-DE), the error in the performance predicted by MPI-SIM-AM was below 16% with the an average error of 11.3%.
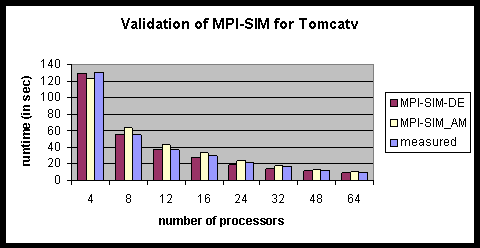
Figure 32: Validation of MPI-Sim for (2048´ 2048) Tomcatv (on the IBM SP).
Tomcatv was processed completely automatically using the full capabilities of both the compiler and simulation system. The same compiler techniques can be applied to MPI codes, but an MPI front-end still needs to be implemented, so the task graphs for the Sweep3D and NAS SP were constructed manually. Here, we aim to show that the compiler techniques we developed can be applied to a large range of codes and produce good results.
Figure 43 shows the execution time of the model for a Sweep3D configuration with a total problem size of 150´ 150´ 150 grid cells as predicted using MPI-SIM-AM, MPI-SIM-DE, as well as the measured values, all for up to 64 processors. As seen from the figure, Tthe predicted and measured values are again very close and differ by at most 7%.
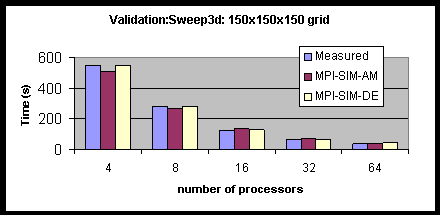
Figure 43: Validation of Sweep3D on the IBM SP, Fixed total Problem Size.
Finally, we validated MPI-SIM-AM on the NAS SP benchmark. The task times were obtained from the 16 processor run of the class A, the smallest of the three built-in sizes (A, B and C) of the benchmark, and used for experiments with all problem sizes. Figures 54 and 56 show the validation for class A and the largest size, class C. The validation for class A is good (the errors are less thanwithin 7%). The validation for class C is also good with an average error of 4%, even though the task times were obtained from class A. A . This is a good result is particularly interesting in light of the fact that because class C runs on the average runs 16.6 times longer than class A, over and above the scaling factor for different numbers of processors. It demonstrates that the compiler-optimized simulator can be expected to beis capable of accurate in projections across a wide range of scaling factorsfrom small to large problem sizes. Furthermore, cache effects do not appear to play a great role in this code or the other two applications we have examined. This is illustrated by the fact that the errors do not increase noticeably when the task times obtained on a small number of processors were used for a larger number of processors.
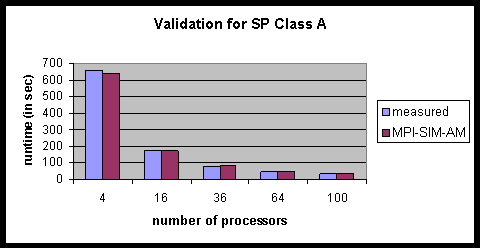
Figure 54: Validation for NAS SP, class A on the IBM SP.
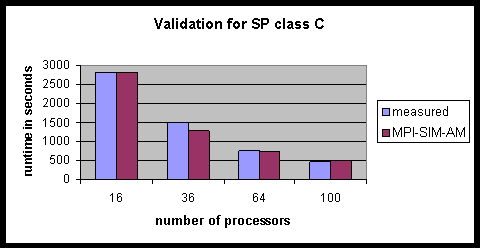
Figure 65: Validation for NAS SP, class C on the IBM SP.
Figure 76 summarizes the errors that MPI-Sim with analytical models incurred when simulating the three applications. All the errors are within 16%. The figure emphasizes that the compiler-supported approach combining analytical model and simulation provides is very accurate for a range of benchmarks, system sizes, and problem sizes.
It is hard to study explore these results errors further without detailed analysis of each application. Therefore, to better quantify what errors can be expected from the optimized simulator, we used our SAMPLE benchmark, which allows us to vary the computation to communication ratio as well as the communication patterns.
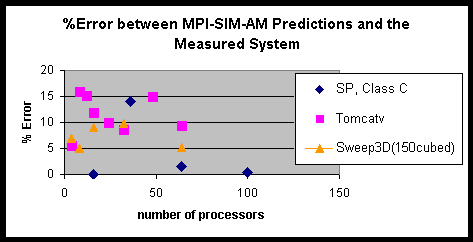
Figure 76: Percent Error Incurred by MPI-SIM-AM when Predicting Application Performance.
SAMPLE was validated on the Origin 2000. Two common communication patterns were selected: wavefront and nearest neighbor. For each pattern, the communication to computation ratio was varied from 1 to 100 to a ratio of 1 to 1. Figure 87 plots the total execution time for the program and MPI-SIM-AM prediction. In order to demonstrate better the impact of computation granularity on the validation, Figure 8 plots the percentage variation in the predicted time as compared with the measured values. As can be seen from the figure, the predictions are very accurate when the ratio of computation to communication is large, which is typical of many real-world applications. As the amount of communication in the program increased, the simulator incurs larger errors with the predicted values differing by at most 15% from the measured values.
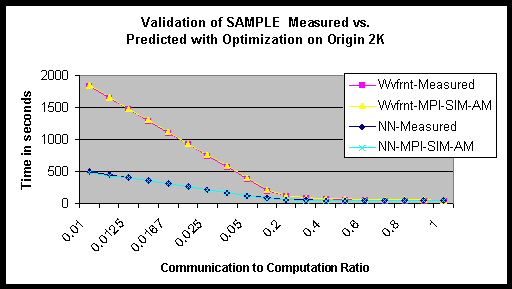
Figure 87: Validation of SAMPLE on the Origin 2000.
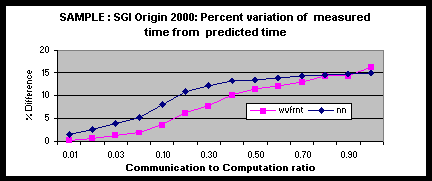
Figure 98: Effect of Communication to Computation Ratio on Predictions.
The accuracy of MPI-SIM-AM for small communication to computation ratio (below 5% error) indicates that some the slightly higher errors we observed for the Tomcatv, Sweep3D and NAS SP benchmarks must come from the errors in task time estimation. Thoese errors might be a result of small computational granularity, where the timers used to measure the task times can inflate the time obtained for a code segment. Cache effects might also introduce errors in task time estimation, although they do not play a great role in the applications we have examined. This is illustrated by the fact that the errors did not increase noticeably when the task times obtained on a small number of processors were used for larger number of processors.
The main benefit of using the compiler-generated code is that we can decrease the memory requirements of the simulatorsimplified application code. Since the simulator uses at least as much memory as the application, decreasing the amount of memory for the application, decreases the simulator’s memory requirements, thus allowing us to simulate large problem sizes and systems..
|
Number of processors |
MPI-SIM-DE total memory use |
MPI-SIM-AM total memory use |
Memory RTimes reduction Factor |
|
|
Sweep 3D, 4´ 4´ 255 per Proc. Problem Size |
1 |
589KB |
6KB |
98.98 |
|
4900 |
2884MB |
30MB |
98.96 |
|
|
Sweep 3D, 6´ 6´ 1000 per Proc. Problem Size |
1 |
33.599MB |
19KB |
176899.94 |
|
6400 |
215GB |
122MB |
176299.94 |
|
|
SP, Class A |
4 |
104MB |
7.36MB |
1492.92 |
|
SP, Class C |
16 |
1596.16MB |
310.08MB |
580.57 |
|
Tomcatv, 2048´ 2048 |
4 |
236MB |
118.4KB |
199399.95 |
Table 1: Memory Usage in MPI-SIM-DE and MPI-SIM-AM for the benchmarks.
Table 1Table 1Table 1Table 1Table 1Table 1Table 1 shows the total amount of memory needed by MPI-Sim when using the analytical (MPI-SIM-AM) and direct execution (MPI-SIM-DE) models. For Sweep3D, with 4900 target processors, the analytical models reduce memory requirements by two orders of magnitude for the 4´ 4´ 255 per processor problem size. Similarly, for the 6´ 6´ 1000 problem size, the memory requirements for the target configuration with 6400 processors are reduced by three orders of magnitude! Three orders of magnitude reduction is also achieved for Tomcatv, while smaller reductions are achieved for SP. This dramatic reduction in the memory requirements of the model allows us to (a) simulate much larger target architectures, and (b) show significant improvements in execution time of the simulator.
To illustrate the improved scalability achieved in the simulator with the compiler-derived analytical models, we consider Sweep3D. In this paper, we study a small subset of problems that are of interest to application developers. They are represented by two problem sizes: 4´ 4´ 255 and 6´ 6´ 1000 cells per processor, which correspond to a 20 million and 1 billion total problem size and need to run on 4,900 and 20,000 processors, respectively.
The scalability of the simulator can be seen in Figures 109 and 110. For the 4´ 4´ 255 problem size, memory requirements of the direct execution model restricted the largest target architecture that could be simulated to 2500 processors. With the analytical model, it was possible to simulate a target architecture with 10,000 processors. For the 6´ 6´ 1000 problem size, direct execution could not be used with more than 400 processors, whereas the analytical model scaled up to 6400 processors. Note that instead of scaling the system size, we could scale the problem size instead (for the same increase in memory requirements per process), in order to simulate much larger problems.
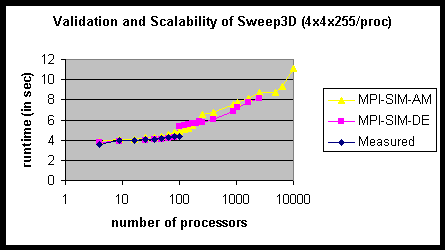
Figure 109: Scalability of Sweep3D for the 4´ 4´ 255 per Processor Size (IBM SP).
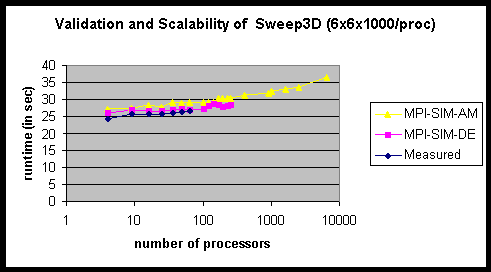
Figure 110: Scalability of Sweep3D for the 6´ 6´ 1000 per Processor Size (IBM SP).
The benefits of compiler-optimized simulation are not only evident in memory reduction but also in improved performance. We characterize the performance of the simulator in three ways:
Absolute Performance
To compare the absolute performance of MPI-Sim, we gave the simulator as many processors as were available to the application (#host processors = # target processors). Figure 121 shows the runtime of the application and the measured runtime of the two versions of the simulator running NAS SP class A. We observe that MPI-SIM-DE is running about twice slower than the application it is predicting. However, the optimized MPI-SIM-AM is able to run much faster than the application, despite performance even though detailed simulation of the communication is still performed. In the best case (for 36 processors), it runs 2.5 times faster. For 100 processors, it runs 1.5 times faster. The reason why the relative performance of MPI-SIM-AM decreases as the number of processors increases is because that the amount of computation in the application decreases with increased number of processors and thus the savings from abstracting the computation are decreased.
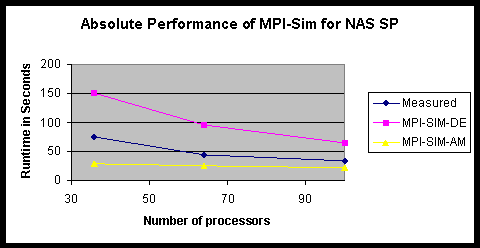
Figure 121: Absolute Performance of MPI-Sim for the NAS SP Benchmark, class A.
Even more dramatic results were obtained with Tomcatv, where the runtime of MPI-SIM-AM does not exceed 2 seconds for all processor configurations as compared to the runtime of the application which ranges from 130 to 10 seconds (Figure 132).
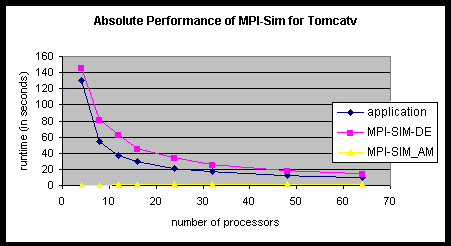
Figure 132: Absolute Performance of MPI-Sim for Tomcatv (2048x2048).
Parallel Performance
So far we have analyzed the performance of MPI-SIM-AM when the simulator had access to the same computational resources as the application. Obviously, when simulating large systems, the number of host processors will be less than the number of target processors, yet the simulator must provide results in a reasonable amount of time. Figure 143 shows the performance of both versions of MPI-Sim simulating the 1503 Sweep3D running on 64 target processors when the number of host processors is varied from 1 to 64. The data for the single processor MPI-SIM-DE simulation is not available as because the simulation exceeds the available memory. Clearly, both MPI-SIM-DE and MPI-SIM-AM scale well. Still, the runtime of MPI-SIM-AM is on the average 5.4 times faster than that of MPI-SIM-DE. The speedup of MPI-SIM-AM is also shown in Figure 154. The steep slope of the curve for up to 8 processors indicates good parallel efficiency. For more than 8 processors the speedup is not as good, reaching about 15 for 64 processors. This is due to the decreased computation to communication ratio in the application. Still, the runtime of MPI-SIM-AM is on the average 5.4 times faster than that of MPI-SIM-DE.
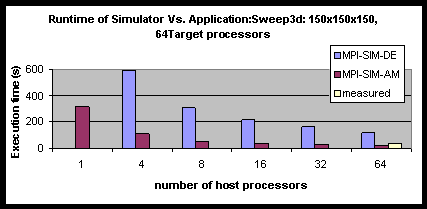
Figure 143: Parallel Performance of MPI-Sim.

Figure 154: Speedup of MPI-SIM-AM for Sweep3D.
Performance for Large Systems
To further quantify the performance improvement for MPI-SIM-AM we have compared the running time of the simulators when predicting the performance of a large system. Figure 165 shows the running time of the simulators as a function of the number of target processors, when 64 host processors are used. The problem size is fixed per processor (6´ 6´ 1000), so the problem size increases with the increased number of processors. The figure clearly shows the benefits of the optimizations. In the best case, when the performance of 1600 processors is simulated (corresponding to the 57.6 million problem size) the runtime of the optimized simulator is nearlyless than half (45%) the runtime of the original simulator..

Figure 165: Performance of MPI-SIM when Simulating Sweep3D on Large Systems.
Conclusions
This work has developed a scalable approach to detailed performance evaluation of communication behavior in Message Passing Interface (MPI) and High Performance Fortran (HPF) programs. Our approach, which is based on integrating a compiler-derived analytical model with detailed parallel simulation, introduces relatively small errors into the predictionsimulation of program execution times. The compiler was used to build an intermediate static task graph representation of the program which enables the identification of computational tasks and control-flow that can be collapsed, and allows the derivation of the scaling functions for these collapsed regions of code. Program slicing was used to determine what portions of the computation in the collapsed tasks can be eliminated. The compiler was then used to abstract away parts of the computational code and corresponding data structures, replacing them with analytical performance estimates. The communication was retained by the compiler and was simulated in detail by MPI-Sim. The benefit we achieve is significantly reduced simulation times (typically more than a factor of 2) and greatly reduced memory usage (by two to three orders of magnitude). This gives us the ability to accurately simulate detailed performance behavior of much larger systems and much larger problem sizes than was possible earlier.
In our current work, we are exploring a number of alternative combinations of modeling techniques. In this paper In the current work, we used an analytical model for sequential computations and detailed simulation for communication. An obvious alternative is to extend the MPI-Sim simulator to take as input an abstract model of the communication (based on message size, message destination, etc.) and use it to predict communication performance. Conversely, we can use detailed simulation for the sequential tasks, instead of analytical modeling and measurement. Within POEMS, we aim to support any combination of analytical modeling, simulation modeling and measurement for the sequential tasks and the communication code. The static task graph provides a convenient program representation to support such a flexible modeling environment [2].
Acknowledgements
This work was performed while Adve was at Rice University. This work was supported by DARPA/ITO under Contract N66001-97-C-8533, "End-to-End Performance Modeling of Large Heterogeneous Adaptive Parallel/Distributed Computer/Communication Systems," 10/01/97 - 09/30/00 (http://www.cs.utexas.edu/users/poems/). The work was also supported in part by the ASCI ASAP program under DOE/LLNL Subcontract B347884, and by DARPA and Rome Laboratory, Air Force Materiel Command, USAF, under agreement number F30602-96-1-0159. We wish to thank all the members of the POEMS project for their valuable contributions. We would also like to thank the Lawrence Livermore National Laboratory for the use of their IBM SP.
References