Figure 10. The Stack Frame
Return to first page of the Compiler Theory article
Once parsing has completed and all data structures are set up, interpreting them is simple. The first step is to implement a separate procedure to interpret each of the ten types of code structures. This implies that procedures must also be implemented to interpret expressions, so that assignment assignment statements and if statements can be interpreted. Finally, there needs to be a general interpret_statement procedure, which identifies the type of code structure being interpreted and calls the correct procedure. This procedure will be called recursively by all other procedures. Once all the procedures are implemented, simply pass the structure holding the main program to interpret_statement.
As an example, we will look at how an if statement is interpreted. First a function call is made to evaluate the if expression. For this we need a function that will interpret boolean expressions and return a boolean value. If the returned value is true, we execute the true path. If the return value is false and there is a false path, it will be executed. Here is the code:
procedure interpret_if_statement (if_stat : if_rec_ptr;
Context : Proc_Rec_Ptr);
begin
if (interpret_boolean_expression(if_stat.Boolean_Exp)) then
interpret_statement(if_stat.True_Path)
else
if (if_stat.Boolean_Exp <> Nil) then
interpret_statement(if_stat.False_Path);
end; {procedure interpret_if_statement}
And that's all there is to it! Recall that the structure we used handle else-ifs as separate nested if statements. So if we have an else-if, the else path will be executed, calling interpret_statement with the nested if statement. Interpret_statement will determine that the statement type is an if statement, and call interpret_if_statement again.
The Context parameter points to the procedure that this code is part of. It is needed to find variables. When a variable is accessed, the find_variable procedure is called with this pointer. Find_variable, which has already been described, searches the local procedure for the variable, then if it is not found, the parent procedure is searched, etc. until global variables are searched. The parser took care of making sure all variables exist, so at this point we should not need to worry about not finding a variable. If a variable is not found at this point it indicates a problem with the parser/interpreter, not with the program being interpreted.
It might be useful to see the code for interpret_statement:
procedure interpret_statement (statement : code_struct_ptr;
Context : Proc_Rec_Ptr);
begin
case (statement.code_struct_type) of
code_block : interpret_code_block (statement.code_blk_ptr,
Context);
assignment : interpret_assignment (statement.assign_ptr,
Context);
proc_call : interpret_proc_call (statement.call_ptr,
Context);
if_stat :
interpret_if_statement (statement.if_stat_rec_ptr,
Context);
.
.
.
Again, this procedure is quite straight forward and simple. The only procedure that is difficult is interpret_proc_call. This procedure needs to set up a copy of local variables and parameters. Remember that every time a procedure is called it needs a new fresh copy of its local variables and parameters, so that recursive procedures will work properly. A new procedure pointer needs to be created with memory allocated for each variable, and the parent pointer pointing to the context pointer passed in to interpret_proc_call. The new procedure pointer then becomes the context parameter passed to interpret_statement by interpret_proc_call.
Return to beginning of Interpretation and Code Generation page
Given the data structures already developed, generating code in high level languages is quite easy and straight forward. A set of procedures similar to those used to interpret code is set up, but instead of interpreting the code, the code is written out. As an example, here is the code to write an if statement in Pascal:
procedure output_if_statement (outfile : text;
statement : code_struct_ptr;
Context : Proc_Rec_Ptr);
begin
write (outfile, 'if (');
output_expression (outfile,
if_stat.Boolean_Exp,
Context);
write (outfile, ') then');
writeln (outfile);
output_statement (if_stat.True_Path);
if (if_stat.false_path <> Nil) then
begin
write (outfile, 'else');
writeln (outfile);
output_statement (if_stat.False_Path);
end; {if (if_stat.false_path <> Nil)}
end; {procedure output_if_statement}
It is easy enough to visualize how other code generation procedures will work. For expression code generation, each procedure calls the code generation procedures for the left side of the expression, then it writes the operator, then it calls the code generator for the right side. There is a minor problem since we are not storing parentheses. This problem can be solved by comparing the precedence of the last operator written and the next one to write. Or the parentheses can be explicitly stored in the parse tree.
The code generated by the example will not be indented. To provide proper indentation an indent parameter can be added. Each time a block of code is nested under another, the indent parameter is incremented by two or three. Before a line of code is written the correct number of blanks is written.
Thus we can see how easy it is to take a Pascal program, parse it, store it in the proper data structures, then write back out the equivalent Pascal program! This is somewhat less than useful, but it is an interesting learning exercise. The data structures developed in this paper are quite generic and can be used to write code in many different languages. This is useful for developing cross compilers or CASE tools that can output code in a choice of different languages. Some compilers actually use this technique as a short cut to compiler development. The classic example is Bell Lab's cfront, the original C++ compiler. This program cross compiles a C++ program to C, then calls the UNIX C compiler to produce object code.
While this technique does work, it is not efficient. The better way is to produce object (binary) code directly. A good solid description of relocatable object code would pretty much double the length of this paper, which is already far to long. So we will only stick to creating assembler here.
The first step in producing binary code is to create global variable declarations. Declaring variables in binary means setting aside memory for the variable and recording the address in the program's data structures. So a field needs to be added to variable data structures to record addresses.
The address where the variable begins is called the base address. If the variable is a record then offset addresses need to be stored in the structures where the record is declared. When a field is accessed in the generated code the offset is added to the base address, giving the true location in RAM where the data is stored.
The next concern in writing object code is writing procedures. Assembler does not support block structured code, but it does not have too. The parser took care of scoping. So these can simply be laid in RAM in whatever order they are encountered as the procedure structures are traversed.
================================================================
The next worry is local variable declarations. This is a little bit of a problem. You cannot simply set aside RAM in the global data space for each procedure's variables. This is what FORTRAN does, and this is why you cannot use recursive programming techniques in FORTRAN. With this approach the parent procedure might set a variable then make the recursive call. The child will then set the variable differently. Since the variable is in the same space for both calls, that is the variable is the same physical variable in RAM, when the child sets the variable the parent will see the variable as changing.
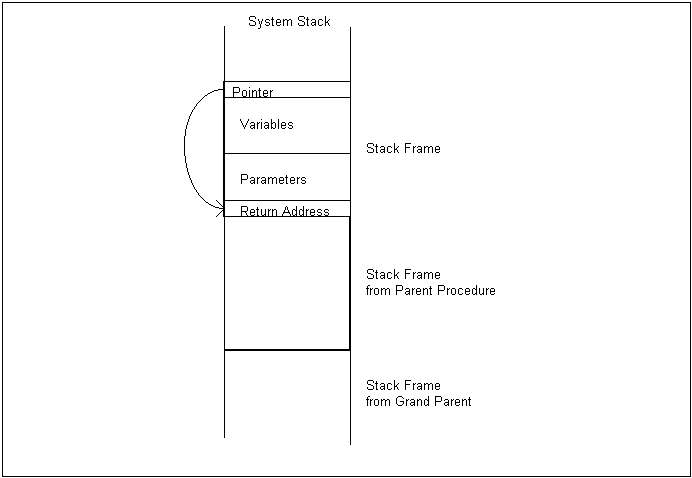
To prevent this, each call to a procedure must be given its own variable space. This is usually done by allocating variables on the stack. When a procedure is called, several steps must take place: The return address is placed on the stack, the procedure parameters are placed on the stack, the local variables are given space on the stack, then a pointer is placed on the stack which points to the location of the return address. This pointer is used to remove the variables and parameters from the stack when the procedure exits. Before the return instruction is issued the stack register is set this value.
All this data on the stack is referred to as a stack frame. Figure 10 shows the stack frame diagramatically:
Figure 10. The Stack Frame
This system of stack frames works for C code, but gets into problems when used with a block structured language. Consider the following code:
procedure my_proc;
Var X : int;
procedure recurse;
begin
X := X + 1;
if (X < 10000) then
recurse;
end; { recurse }
begin {my_proc}
X := 1;
recurse;
end;
Given the nth call to recurse, how is X found? Remember that X is on the stack somewhere, not in global variable space. Obviously a more sophisticated stack frame is needed. I have never implemented a parser for a block structured language, and do not know how this is accomplished.
=================================================================
Next we have to worry about creating expressions in assembler. The first step is to break the expressions in the parse tree into a series of binary expressions, that is expressions that each have one operator and two operands. Figure 11 shows a complex expression from figure 3, and the equivalent binary expressions:
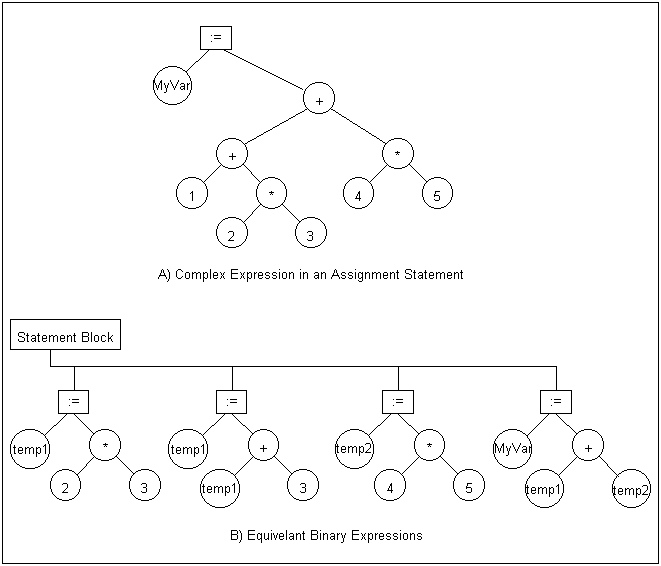
Figure 11. A Complex Expression and Equivalent Binary Expressions
Notice that the multiply is done first, reflecting the precedence of the complex expression. It is important to keep the precedence intact. Notice also the use of two temporary variables. When generating assembler code, registers are used. The temporary variables are processed and associated with registers. At this stage it is important that we do not reuse temps. Each temporary variable should be assigned a unique name. Later processing will take care of minimizing the use of registers or temps. This expression requires two registers.
Generally a register table is set up, with one entry for each available register. Each entry contains a flag to show whether the register is available or not, and a temp name which the register is associated with. The code for each procedure is traversed separately, and whenever a temp is encountered on the left side of an assignment the table is traversed and the first available register is substituted for the temp. That register is now associated with that temp. Whenever a temp is found on the right side of an expression the register table is searched to find the register associated with the temp. If a temp is found on the right side of an expression and there is no associated register in the register table, that indicates a bug in the routine that breaks expressions into binary expressions.
Once a temp is no longer used, its associated register should be made available for association with another temp. There are two methods to accomplish this. The first is to locate the final use of a temp, and at that point clear the used flag in the register table. This requires an inefficient search to the end of the procedure to locate the last use of the temp. After the register is freed the next temp found on the left of an assignment will automatically use that register.
The second method is to locate the last use of a temp, then rename the next temp created to be the same as that temp. Then when register replacement takes place the register will automatically be associated with the temp already. This also requires an inefficient search of the code tree.
In order to minimize these inefficient searches, code can be arranged in such a way that all registers are cleared after each statement. This way only the statement code need be searched for the last use of a temp, not all the code to the end of the procedure. This also simplifies procedure calls, since you do not need to worry about the procedure modifying registers in which you have stored vital data. This greatly simplifies code generator design, but can lead to less efficient code. Optimizing compilers often take the other approach, where time and effort is spent to keep as much data as possible in registers for as long as possible. This is a difficult thing to do, since a balancing act is always necessary to keep this procedure's register data from being corrupted with the called procedure's register data. (Readers interested in this style of code generation might want to check out Sun Workstation's SPARC architecture. This architecture has a unique way to uncomplicate such register handling. The link here is to Sun's home page, I did not dig around long enough to find a page specifically on SPARC architecture).
However registers are allocated there is always a chance of running out. When this happens temps can be placed on the stack. This will slow execution, but the alternative in this case is to stop code generation with an error. On time critical tasks, however, stopping code generation because there is not enough registers might be the only alternative.
Return to start of this page
Return to Table of Contents of the Compiler Theory article
I would like to thank the hearty readers who have made it through all this data to the end of the paper. Due to the length of the paper, I have placed my e-mail address at the beginning of the paper, rather than here at the end. Please feel free to write with questions, comments, and especially with corrections. I am well aware that there are technical details that may well be in error. Never-the-less, this paper does give an accurate feel for what goes on inside of a compiler. As was said in the introduction, it is not intended to be complete and all inclusive. It is, rather, intended as an introduction.
Thanx, JAF
9/7/95
Return to Table of Contents of the Compiler Theory article
Return to High Tech page