Figure 9. Data Structures holding A Parsed Program
Parsing Procedures and Scoping
Return to first page of the Compiler Theory article
At this point, parsing procedure declarations should not look difficult. There needs to be a table that holds the procedure's declaration. This table will hold all procedures declared on a particular level. When a procedure declaration is parsed it is entered into this table. Pascal supports forward declarations, so before a new entry can be made in the table it must be searched to see if the entry is already there.
Functions are usually held in a separate table, since they are handled somewhat differently from procedures. The requirements for the function table are the same as for the procedure table.
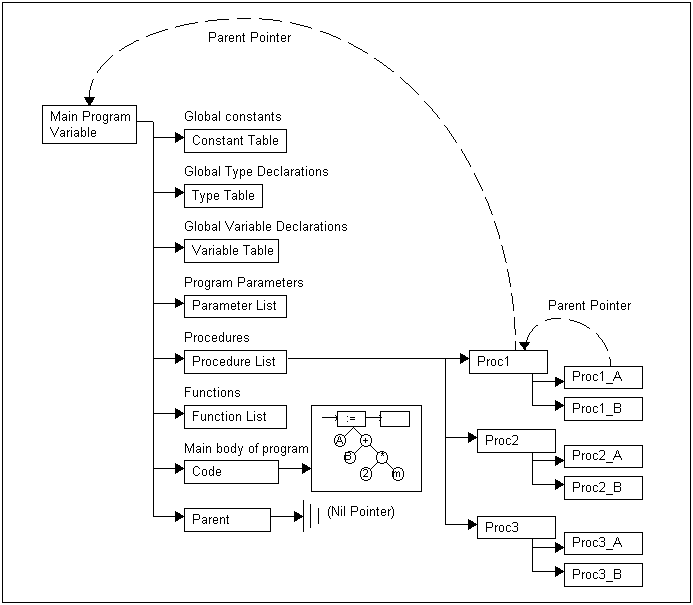
Each entry in the procedure table must contain tables of parameters; locally declared constants, types and variables; and locally declared procedures and functions. There also needs to be a code_struct_ptr.
In addition to these fields, there needs to be a pointer to the procedure's parent. This pointer is used to find variables that are not declared locally. If a variable is referenced in an expression, the local variable, function and parameter tables are searched for the variable (in Pascal the parser cannot tell the difference between a variable reference and a function call until the variable is found in a table). If it is not found, the parent_ptr is used to find the parent procedure's variable, function and parameter tables. If the variable is not found there, the parent's parent_ptr is used to go up another level. Eventually the outer most (program) level is reached, and the table of global variables is searched. If the variable is not found here an undeclared variable error is raised.
The process for locating a procedure call is basically the same as for locating a variable.
The data structure to hold a procedure looks something like
proc_list_ptr = ^proc_list;
proc_rec_ptr = ^proc_rec;
proc_list = record
proc : proc_rec_ptr;
next : proc_list_ptr;
end; {record}
proc_rec = record
local_consts = const_decl_table_rcd_ptr;
local_types = type_decl_table_rcd_ptr;
local_vars = var_decl_table_rcd_ptr;
parameters = parm_list_ptr;
sub_proc_list = proc_list_ptr;
sub_func_list = func_list_ptr;
code = code_struct_ptr;
parent = proc_rec_ptr;
end; {record}
In this example the parameters, sub-procedures and sub-functions are held in lists rather than trees. If the program is designed correctly, according to good software engineering standards and practices, there will not be a large number of any of these. The overhead and programming effort needed to implement a table is not necessary for these. Today much software is developed using powerful programming tools that provide ready made and very efficient table structures, so most compilers being created today do actually use tables for these fields also, simply because they are available.
In Pascal, the program as a whole has basically the same structure as a procedure, so the record shown here is also used to store the program. Thus we have a single variable that holds the entire program being parsed, or at least a single variable that contains pointers to pointers to pointers, etc. By going through this single variable every single item declared in the program can be accessed. The program variable sets the parent pointer to nil.
Given these structures, we can show diagramatically how the parsed program is stored (figure 9).
Figure 9. Data Structures holding A Parsed Program
Detail is not shown for the procedures, because that would make the diagram to cluttered. It is important to remember that they are kept in records that are exactly the same as the main program variable. Thus an entire program can be stored.
Note the back pointers from proc1_a to to proc1 and from proc1 to the main program. These are used as a pathway to locate variables that are not local to the procedure. Take a look at the following program skeleton, which matches the diagram.
Program try;
Var
X : int;
procedure Proc1;
var
X : int;
procedure Proc1_A
var
X : int;
begin
end;
procedure Proc1_B
begin
end;
begin
end; {proc1}
procedure Proc2;
procedure Proc2_A
begin
end;
procedure Proc2_B
begin
end;
begin
end; {Proc2}
procedure Proc3;
procedure Proc3_A
begin
end;
procedure Proc3_B
begin
end;
begin
end; {proc3}
begin
end. {program try}
Procedure Proc1_A declares an integer variable X. When this variable is referenced, the parser needs to look up the variable in the procedure's local variable table, where it will be found. If Proc1_B references an integer X, the compiler will look in Proc1_B's local variable table, but it will not find it. The compiler will then trace the parent pointer, and look in Proc1's local variable table, where X will be found. If proc2_A references X, the parent pointer will be traced to Proc2, where X will not be found. Proc2's parent pointer will then be traced to the main program, and the globally declared X will be used.
It is handy to create a procedure that will always find the correct variable reference from the given scope. That is, the procedure structure that holds the variable reference is passed to the variable locator, and the locator will search from there until the variable is found, returning a pointer to the variable. If the variable is not found the function list must then be searched by a second procedure, the function locator. Again, if the function is not found the parent must be searched. If no variable or function is found an error is raised. Note that the variable locator must also search the parameter list. Consider what to do if there is a variable and a parameter with the same name.
For our discussion of object oriented parsers we will be using the LOOP (Language for Object Oriented Programming) programming language. When I first wrote this paper, I was working on LOOP as a language to train new programmers. The intent was to create a language more modern and powerful than Pascal, but easier for a beginning programmer than C++. Due to other pressures, I have dropped the project (for the time being), but it will still serve for our discussion here.
LOOP organizes all data into classes. A class contains data members and the procedures needed to operate on those data members. Classes are similar to Pascal types, in that they do not actually contain data, they are merely templates. When an object is instantiated the class of the object is used to set the data and procedure members of the object.
Since classes are similar in behavior to Pascal type declarations, they can be handled by similar structures, modified to handle the special object oriented features. Objects can similarly be handled by structures similar to those for Pascal variables.
There are several features that are unique to object oriented languages that the compiler designer must deal with. First of all, LOOP allows for procedure and function overloading. This means that different procedures contained in the same object can have the same name, as long as their parameter lists are different. This means the procedure and function lookup tables will need to be a little more complex. One solution to this problem is to store all procedures with the same name in a list. The head of this list is the node for the procedure name in the procedure table. The name itself does not need to be stored in the list, only in the table node. The procedure that searches for a particular procedure will need to be modified to compare the types of each parameter with those in the parameter lists of each candidate procedure.
In Pascal, procedure forward declarations allocate a procedure in the procedure table. When the procedure itself is parsed the body of the procedure is filled in. Things are rather more complex in an object oriented language. Here all procedures are first declared (prototyped) in the class definition, and the code is given elsewhere. Different procedures in different classes can have the same names and parameter lists. When a procedure is called, the class's local procedure list must be searched for the correct procedure. A pointer must be stored in the procedure table, indicating the correct procedure. If a nonlocal procedure, that is a procedure declared in a different class, is called, it must be preceded by an object and a dot.
Loop handles arithmetic operators as a specialized type of function. This treatment combined with function overloading implies that arithmetic operators can be overloaded. An example of this is the '+' operator on strings. The LOOP language does not supply an intrinsic string capability, but instead a standard string class is defined, which can be supplied in its own source or object code files. This class defines the '+' operator to be the cantonation of two strings. The integer and real classes both define the '+' as the standard arithmetic operator. Such operator overloading is common in object oriented languages. While overloaded operators are handled as a specialized function type, they are stored in a separate table.
Parsing overloaded operators in an expression (as opposed to in a declaration) is a little more interesting than parsing overloaded procedure calls. As the expression is parsed, the class (type) of the leaf node of the parse tree (the bottom level, which must be a variable, constant or function call) must be returned back up the parser's calling structure (remember all those recursive procedure calls we looked at many pages ago?). The parser then goes and parses the right hand side of the expression, which returns a second class. The overloaded operator table of the first class is searched to see if any overloaded operator has the second class as a right hand parameter. If one is found, that is the function that is called. The return type of that function is then returned by the parsing procedure.
The next aspect of object oriented languages that we need to look at is inheritance. LOOP syntax specifies that inherited data and procedure members be enumerated. Procedure members must be spelled out with complete parameter lists. This allows each inherited member to be placed in this class's data and procedure tables. For reasons explained below, we cannot simply place a pointer to the function itself in the table, but instead we must use a pointer to the parent class's procedure table.
Why all the pointers to pointers to procedures? Because in LOOP all procedures are virtual, meaning the actual procedure used by a class has the ability to change at runtime. When a class inherits from a parent class we say the definition has narrowed. Sometimes there will be several narrower definitions of a parent class, and we will not know until run time which narrower definition will be used. So we declare an object of the parent class, but instantiate it as one of the child classes. We do not know which actual procedures the object will use until it is instantiated.
The implications of this are rather deep. This means that the procedure table for each class must be stored in the executable code. Each time an object is instantiated, for each procedure declaration the correct procedure must be located and its address placed into the table. Procedure calls will involve locating the procedure address in the table, then making a call to the address. This is referred to as indirect procedure calls. Storing procedure tables and calling by address will be touched on in the code generation section.
Indirect procedure calls tend to make object oriented languages less efficient than standard languages. C++ gets around this partially by making only certain calls indirect. In C++ a function must be declared as virtual, where in LOOP all functions are virtual. LOOP was designed as a "training language", so the designer was less concerned with the efficiency of the final program.
In the example parser code, the error handling has been quite lame. There have been calls to procedures such as raise_syntax_error(token). These should generally be considered simply markers as to were error handling should be used.
The problem with this approach is that there is no way for the parser to continue. An error is detected, and a procedure is called that will "raise an error" - notifying the user that something is not right. The parser will then attempt to continue, but things are still not right, and another error will be raised, then another and another, etc. If we were to write a compiler with this philosophy it would have to terminate on the first error. The user would then go correct that error and re-run the parser. When the next error is found the parser will terminate and the user has to go fix that error. This is a frustrating process, as any one who has ever used such a compiler will attest (early versions of Turbo Pascal were like this).
A better method would be to enable the parser to continue somehow, and when parsing is complete a list of errors would be written out. This can be accomplished by creating a procedure that will consume tokens until a recognized token is reached. Once the recognized token is reached the parser needs to get to a state where it can continue from that token. This process is called resynchronization and parsers that do this are called resynchronizing parsers.
The easiest way to see this process is with an example. Imagine the following Pascal statement, which is a syntax error:
My_Var := A + * B + C;
The parser will read the first +, then attempt to read a factor (i.e. a number, constant, variable or parenthized expression), but it does not find one. It then calls the raise_error procedure which has the responsibility of notifying the user of the error, then it calls the procedure resynchro_symbol, which consumes tokens until the semicolon is reached. At that point the expression parser exits. The following code from parse_factor illustrates:
if (token.token_type = reserved_sym) and
(token.res_sym = open_paren) then
begin
advance_token(token);
parse_expression (exp, token);
if (token.token_type = reserved_sym) and
(token.res_sym = close_paren) then
advance_token(token)
return;
else
(* this is an error - missing closing paren *)
error_raised := TRUE;
raise_error (token, 'Closing paren expected');
resynchro_symbol (token, rs_semicolon);
return;
end;
(* if we got here, then there was an illegal element in *)
(* expression. Raise an error *)
error_raised := TRUE;
raise_error (token, 'Variable or Constant Value Expected');
resynchro_symbol (token, rs_semicolon);
return;
Error_raised is a parameter that has been added to all parsing procedures. It is used by the calling procedures to aid in resynchronization. The procedure raise_error creates a list of errors containing the location of the error in the input stream and the error message string which is passed in. Recall that our token structure contains the location of the current token in the input stream. Resynchro_symbol, as already described, consumes tokens until the expected token is found.
In order to deal with errors, the other procedures in the expression parser need to be modified. Here is the code in parse_term that calls parse_factor:
advance_token(token);
parse_factor(exp.right_expr, token, error_raised);
if error_raised then
return;
Such error checks will cause the entire expression parser to be exited. Control will return to the assignment statement parser, which sets error_raised back to false, indicating that the parser has resynchronized and parsing can continue.
In addition to resynchro_symbol, a resynchro_reserved_word procedure is usually needed.
The general method to handle errors is to identify the error, raise an error message, consume tokens until a token is found that the parser can resynchronize on, then exit procedures up the calling chain until we reach a point were the word or symbol we resynchronized on would naturally be expected.
The word or symbol we resynchronize on depends on where exactly the error is found. If we detect an error in an expression then resynchronizing on a semicolon is a reasonable thing. If the error is detected in a record declaration we might resynchronize on the word "end", bypassing the entire rest of the record declaration. Errors in procedure declarations often cause the entire procedure to be by passed.
In real life we often find that more than one level of error handling is needed. For instance, if we assign an integer to a real we might want to warn the programmer, but this is not an error and we can continue. To deal with such situations another parameter is added to raise_error, to designate the level of the error. If the error is a warning the resynchronizing procedure does not need to be called. Most compilers implement at least three levels of errors: Warnings allow parsing to continue and code to be generated, Errors require resynchronization and block code generation, and Fatal Errors cause the parser to immediately exit.
These methods of handling errors are far from perfect. Often times a single error in a program will lead to many error messages, some of them far removed from the actual error. This happens when the compiler does not resynch correctly. No compiler can ever predict everything that a human being might do to a program, so even high quality professional compilers that have been available for years have problems of this nature. In order to prevent too many problems of this nature a fatal error is often raised after a certain number of errors are encountered.
Developing a resynchronizing parser is not easy. There is as much art as skill in knowing what to resynch on in a given situation. When you have a compiler giving you goofy error messages that do not seem related to the actual problem be patient, don't complain until you've written a better resynching mechanism yourself!
Go to next page (last page!) of Compiler Theory article
Return to start of this page
Return to Table of Contents of the Compiler Theory article
Return to High Tech page