



Next: Expressions: Operators
Up: CS2111: Design and Implementation
Previous: CS2111: Design and Implementation
Contents
Subsections
Introduction
In many circumstances, an effective way of communicating with a program
(e.g. to issue commands, to input data, etc.)
is to use a textual interface.
Implementing such an interface often means designing a language and software
that accepts and obeys this language.
This course unit examines programming languages, and in particular imperative
languages, looking at the fundamental concepts they have in common,
and outlining how to implement them.
We also look at the variations in these concepts between languages, and see
how this affects usability and ease of implementation. We will investigate
these concepts using examples from various languages, particularly C and SML,
rather than examining complete languages in turn.
The aim is that by the end of the course unit, you
- can design and implement textual interfaces for your programs
- have a head start on understanding new programming languages
Examples of Language design - declaring and using variables and strings
char a = 'A';
char* abc = "A B C";
printf ("%c=a %s=abc\n", a, abc);
Example C fragment
|
set a = A
set abc = "A B C"
echo $a=a $abc=abc
Example CSH fragment
|
a = A
abc = A B C
echo $a=a $(abc)=abc
Example MAKE fragment
|
|
commands 
Interpreters
execute/obey input
|
|
input
output
Translators
transform input to the output
|
|
Programs often consist of a series of filters,
perhaps followed by a final translator or executor.
GREP and EGREP
GREP echoes lines from the input(s) that match a pattern.
Each input line is processed in turn:
characters on each line are scanned for patterns,
and if a pattern is completely recognised, the current line is output.
Metacharacters (characters with a special meaning)
\ ^ $ . [ ] * + ? | ( )
| any non-metacharacter |
recognise that character |
\any metacharacter |
recognise that metacharacter |
\n or \t |
as for C - newline or tab |
^ |
beginning of line |
$ |
end of line |
. |
any one character except newline |
[ ] |
any one character from inside the brackets |
| |
indicate ranges by - e.g. [a-zA-Z] |
| |
an actual ] must be the first character |
| |
an actual - must be the first or last character |
[^ ] |
any one character except . . . |
| anything* |
anything repeated none or more times |
| extra facilities in EGREP: |
|
anything+ |
anything repeated one or more times |
anything? |
anything repeated none or one times |
one | another |
either one or another |
( ) |
recognise the contents |
<>
precedence:
[ ] ( ),
* + ?, concatenation,
|
We will examine these two programs in a lot more detail later, as they are
very useful for implementing computer languages. The major part of their
languages are patterns and corresponding pieces of C code (actions).
- unlike GREP, they do not need to process the input line-by-line,
- we normally expect their patterns to match the whole of the input,
- as each pattern is completely recognised in the input, the corresponding
action is obeyed.
The major difference between LEX and YACC is the way the
patterns are described - LEX is similar to EGREP, but
YACC is very different.
A translator, whether human or machine, has to understand what it is
translating.
Because we can normally rely on the common sense and shared experiences of
other human beings, natural languages can be ambiguous, fuzzily structured
and have large vocabularies.
In contrast, not only do computer languages have limited, mainly
user-defined vocabularies, but also we have to exactly specify the legal
forms of each construct of the language and what it means, both alone and in
combination with every other construct.
Representation and Meaning
The meaning of a + b is usually along the lines of:
"take the values associated with the identifiers a and b, combine those two
values into one by addition, and have the resulting value ready for further
use"
This typical meaning may be modified in many ways e.g.:
- "first take the value... a, then take the value... b, ..."
- "...convert the values so they are compatible..."
- "...combine the values by set-union/ string-concatenation/
matrix-addition..."
This meaning can be represented in several ways e.g.:
a + b [infix]
a b + [postfix/Reverse Polish Notation]
+ a b [prefix]
add a b
add (a, b)
(add, a, b)
add a and b
a plus b
Users want every sensible meaning to have a straightforward representation.
Implementors want every possible representation to have a reasonable meaning.
We normally refer to the representation as the syntax, and the
meaning as the semantics, and there are various informal and formal
notations and concepts we can use to help us define them for a particular
language. I will avoid using formal notations for semantics, but we will be
using various software tools (LEX and YACC) to help with
syntax, each of which has its own notation.
Semantics is itself usually split into two parts:
- static semantics (or semantics or context)
- the meaning of a program that is apparent when it is read as a piece of text
by a human or a compiler
- dynamic semantics (or run-time behaviour or semantics)
- the meaning of the program that is apparent as it is running
Thus, important features common to most computer languages are:
- structure
- (syntax) described by grammars;
normally implemented using parser-generators
- identifiers
- (static semantics) bind meanings to strings in a scope;
implemented using a dictionary.
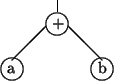
A 2-dimensional representation. They make the relationships between operands,
operators etc. explicit, and so are clearer than the linear notations above.
However, we still need extra information about the meaning, such as the order
in which operands are accessed. e.g. parse tree for a + b
- Any metacharacters of GREP or EGREP that are also
metacharacters of the shell you are using have to be quoted.
Which characters are these?
- Choose some complicated expressions and for each
- fully bracket it
- write it using the other representations in
 1.5.1
1.5.1
- draw the corresponding parse tree
Try expressions involving functions calls and data structure accesses - see
if you can find different ways of drawing the parse trees for these by
making different assumptions about which parts of the expression are the
operators.
- Use the MAN command to find out more details about MAKE,
GREP, EGREP, and whichever shell you normally use
(probably BASH) e.g. type
man make etc.
Use GREP or EGREP on some text files e.g. to list all
the Subjects of all your email.
Write a shell command file to compile and run any program you wrote e.g. for
a first semester lab.
Convert your shell command file into a MAKEfile, that can compile and run
your program as two separate steps. Add a third entry to the MAKEfile to
keep the output from the run and DIFF it with a previous output,
so you can immediately see the consequences of any change to your program.
Bal & Grune: chs. 1, 7.2.2 Louden: chs. 1, 2
Capon & Jinks: ch. 1 Aho, Sethi & Ullman: ch. 1
Rationale for ANSI C FAQ for comp.lang.c
Next: Expressions: Operators
Up: CS2111: Design and Implementation
Previous: CS2111: Design and Implementation
Contents
Pete Jinks
1999-09-30