label:
goto label
if (expression) goto label
call procedure(...)
... function(...) ...
Labels and functions etc. might be numbered or named. Some languages did not
use parameters, instead communicating via global variables. Many early
languages also provided some sort of for-loop, originally intended for
stepping through arrays.
However, bitter experience showed that allowing jumps to be made from any point of a program to any other point is a bad idea; it disperses logically related parts of the program, it obscures the flow of control so that we cannot decide which routes through the code are actually possible, and it encourages jumps into the middle of otherwise working constructions, violating their preconditions and generating untraceable bugs.
One part of language design became the search for higher-level control structures, to replace as many uses of jumps as possible. Many different structures were proposed, often specific to a particular programming style or problem. Many users were suspicious of this trend, believing that power and efficiency were being lost.
Böhm and Jacopini proved that any program containing jumps can be converted to an equivalent program using only loops and if-then-elses, provided some extra boolean variables are introduced. However, their proof did not show how to make best use of these control constructs.
Dijkstra proposed that only three control constructs should be used: concatenation, selection and repetition:
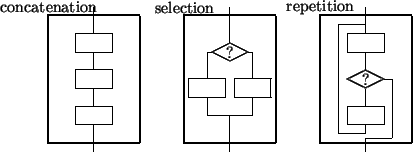
;,
with some of these treating it as a separator
and the rest treating it as the statement terminator.
To turn a code sequence into a single entity, usually known as a
compound statement,
some languages use an explicit pair of brackets, such as { }
or begin end,
as a general form useable with any structure.
Some languages have specific forms for each structure, such as if fi
(or if end_if) and while od (or while end_while).
Some languages have both general and specific forms,
and others have neither.
Because structures often end up deeply nested, specific keywords can be much
easier to pair up than general pairs. (c.f. ![]() 9.2.1)
9.2.1)
if statement/expression, and
almost all languages have it, usually in two slightly different forms such
as if then and if then else.
(c.f. dangling else then and else parts,
but most modern languages have no such restrictions, allowing nested if
statements.
One common pattern of use is:
if ... then ...
else if ... then ...
else if ... then ...
. . .
else ...
and this has given rise to a different kind of selection construct, the
case or switch. This first arose as a modified goto:
goto label_array[n]
but this was even more dangerous than normal gotos, and was also replaced. A
switch construct is essentially a list of (value, action) pairs. Different
languages have different forms of this construct:
We can generalise the switch into a block of guarded statements, where at most one of the statements is obeyed e.g.:
if
i < j then j -= i
j < i then i -= j
end
We can even allow for more than one of the guard expressions being valid,
either by picking the first such in the list, or by non-deterministically
picking a valid guard at random.
Loops come in two forms: indeterminate, where the number of repetitions is unknown until the loop terminates, and determinate, where the number of repetitions is known when the loop starts. Again, some languages with iteration have both forms, some only one or the other.
Dijkstra's (indeterminate) repetition construct, which involves a test in the middle of the loop, is not often directly implemented in programming languages. However, special cases of it are common: a version with the first box missing so the test is at the start is found in most languages, and a version with the last box missing so the test is at the end is often found as well.
Almost all languages provide some sort of determinate loop, usually known as
a for-loop or do-loop.
The basic form is a loop that e.g. counts from 1 to 10, and some languages
provide little more than this: e.g.:
for i := 1 to 10 do...
and because of this some languages
do not bother to test the condition until the end of each repetition. Various
enhancements exist: variables or expressions for start and stop values,
increments other than 1, decrements, automatic declaration of the counter
variable, scalar types other than integer. Some languages guarantee a
particular value of the counter outside the loop or permit it to be modified
inside the loop, whereas others do not, so as to allow for optimisations (and
because modifying the counter does not lead to good quality code).
We can transform the while statement into a loop containing a list of guarded statements, that repeats until none of the guards is valid e.g.:
while
i < j do j -= i
j < i do i -= j
end
This example terminates when i equals j.
Then, at any point in any box (even from inside nested boxes), we can complete the box, by jumping to the end of it, or repeat the box by jumping to the start of it. (We never jump into a box from outside it.)
Ideally, we would name control structures and use those names in the
completers and repeaters: e.g.
fred: if... then... complete fred ...else... repeat fred ...
This facility is not common, and the best we usually have is something like
C's break and continue statements; these can only be used with loops and
(for break only) switches, and can only exit one nested structure. However,
this does mean that they can be invoked inside nested if statements.
(C also has the return statement, to complete functions, and exit, to
complete the whole program.)
In most languages, we can only use explicit labels and gotos, with all the
attendant dangers.
There are two main ways of reporting such errors so they can be dealt with. The simplest, as used by C and Unix, is to return a result from every function that can be checked by the user. However, it is too easy for the user to forget to check, or simply to assume that a particular operation cannot fail. Also, this mechanism cannot deal with other kinds of error, such as arithmetic overflow or division by zero.
The other main way of reporting errors is that used by SML: exceptions.
Exceptions (i.e. kinds of errors) can be declared by the user or the system, and raised when the error occurs. Various pieces of code can provide handlers for any given exception, and various rules decide which handler should be invoked. Thus the system can define a default handler that reports an error and terminates the process, and the user can handle specific errors that should not be so catastrophic.
In Ada, exception handlers can be defined just before the end of any block e.g.:
begin
open(file);
when open_file_error =>
begin
open(file2);
when open_file_error => put ("can not open file");
end;
end;
If exceptions or the equivalent are not available, facilities like C's setjmp/longjmp can be used to deal with errors.
Dijkstra: Goto considered harmful
CACM V11 #3 pp.147-148 (March '68)
Dijkstra: Notes on structured programming pp17-19
in Dahl, Dijkstra & Hoare: Structured programming
Academic Press 1972
Böhm & Jacopini: Flow diagrams, Turing machines, and languages with only
two formation rules
CACM V9 #5 pp.336-371 (May '66)