I intend to try to give you some answers to the following questions:
Natural languages, such as English, are ambiguous, fuzzily structured and have large (and changing) vocabularies. Computers have no common sense, so computer languages must be very precise - they have relatively few, exactly defined, rules for composition of programs, and strictly controlled vocabularies in which unknown words must be defined before they can be used. It is a major goal of research in Artificial Intelligence to find out how to make computers understand natural languages, and the more we learn, the harder it seems to be!
Sometimes we have to use assembly language (Low-Level Language, LLL) because there just isn't any other sensible way of telling the computer what it must do. However, most programming is done in High-Level Languages (HLLs), so what benefits does this bring? The most important answer is productivity - it is usually easier, or more cost-effective, to use a HLL. Some of the reasons for this are:
Different kinds of languages emphasise different things about the problem, and so are better at describing different aspects of the solution, or even different kinds of problems and solutions. Computer Science is ever-changing, so there is continual evolution of the concepts we need to use and the notations for describing these concepts.
For example, Operational languages express how something is achieved, and make the reader work out what is being achieved. Declarative languages express what must be achieved, and make the system work out how to achieve it.
The earliest languages had few restrictions, so they were very powerful, but turned out to be very dangerous to use. After a while, people developed languages that were much safer to use, but there were complaints about their lack of power. Nowadays, we are starting to see languages that are both safe and powerful, but the process has a long way to go yet.
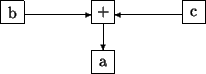
a = b + c
(set a, (add b, c))
b c + a =
ADD b TO c GIVING a
PAR
to_a ! b + c
to_a ? a
The very earliest languages had to be based on something, and that was probably simple instructions give to humans without much vocabulary or common sense i.e. children. The basic ideas are about describing state (e.g. the current state, or a desired next state, of a particular set of things), the actions that modify the state, and the sequence of the actions. In a computation, state is represented by the values of registers (PC etc.) and memory (variables etc.). e.g. making tea:
declare kettle, teapot, water, tea_leaves; kettle= water; boil (kettle); teapot= tea_leaves; teapot= teapot + kettle;
However, although this is intuitive for simple problems, it became clear that this did not scale well - i.e. it becomes disproportionately hard to use as problem size increases. To determine whether a program will work correctly, we must examine e.g. all possible combinations of actions on all of the state.
To reduce the number of possible combinations, we can control:
which actions are permitted on different parts of the state
- type checking
whereabouts in the program particular actions can be used or parts of the
state accessed - scope
Increasing awareness of scope and type checking carried language design in two directions. The main stream of language design included these ideas in most programming languages, and gave rise to new programming paradigms which maximised the control over state (objects), or minimised the use of state (functional, logic). However, as the problem became better understood, it became clear that in some situations it could be an advantage to avoid scopes and types altogether (scripting).
This is similar to Imperative but with maximum use of types & scopes - keep state in objects, each type of object (class) having its own set of actions (methods). Furthermore, the state in an object can often only be accessed or modified via its associated methods.
Functional languages emphasise the transformations of values (so the notation usually makes it easy to describe & examine values):
let boiling_water = boil (put_in (kettle, [water])) in put_in (teapot, [tea_leaves, boiling_water]) endIn particular, values don't have state, so they can be substituted freely:
put_in (teapot, [tea_leaves, boil (put_in (kettle, [water]))])
make(Con,tea):-water_proof(Con),heat_resistant(Con), contains(Con,tea_leaves),contains(Con,boiling_water). source(tea_caddy,tea_leaves). source(tap,water). source(Con,boiling_water):-canboil(Con),contains(Con,water). contains(Con,Item):-source(Con,Item). contains(Con,Item):-source(Con2,Item),move(Item,Con,Con2). canboil(kettle). water_proof(teapot). heat_resistant(teapot). move(Item,Con,Con2).If we ask ``can we make tea in a teapot'' by typing
make(teapot, tea). the system answers yes,
or if we ask ``what can we make tea in'' by typing
make (X, tea). we get X = teapot
We can even get the system to tell us how to make tea:
move(Item,Con,Con2):- write('move '), write(Item),
write(' from '), write(Con2), write(' to '), write(Con), nl.
canboil(kettle):- write('boil kettle'), nl.
and make(teapot, tea). will output:
move tea_leaves from tea_caddy to teapot move water from tap to kettle boil kettle move boiling_water from kettle to teapot
Another difficulty with Imperative programming was the concept of sequence - there are many circumstances where the exact order of some actions does not matter, as long as they are all done before we progress to the next step. In parallel languages, if actions don't interact, work on them in any order (non-determinism), or even simultaneously (multi-processing).
CHAN OF ANY to_pot, to_kettle, kettle_to_pot, to_cup:
declare boiling_water:
PAR
declare water:
SEQ -- kettle
to_kettle ? water
boil ( )
kettle_to_pot ! boiling_water
declare tea_leaves:
SEQ -- teapot
PAR
to_pot ? tea_leaves
kettle_to_pot ? boiling_water
to_cup ! tea
So far, we have been thinking about languages suitable for solving very large problems, where the resulting programs are tens of thousands or more lines long, written and maintained by more than one person. However, not all problems require industrial-strength solutions, and different requirements have given rise to different kinds of languages. The situations where they are applicable are:
The resulting languages are greatly simplified from the programmers point of view, so that ``scripting languages make programmers of us all''. A major design pressure is to minimise the amount that users have to write, and therefore that they can get wrong. In particular, they minimise the use of declarations, and thus the use of types or scopes - they often only have one type, the string (so numbers are held as a series of digit characters). This reduces the usefulness of compilation, and means that more work must be done at run-time, so these languages are often interpreted (and thus run much more slowly). They are often used to write simple little programs that are unlikely to ever be run again.
The earliest such languages were precursors to what we now know as CLIs or shells. Many of the thousands of existing programming languages are scripting languages designed to control specific applications. Widely-used scripting languages include AWK, Bash, JavaScript, Perl, Python, Rexx, and Tcl. Some of the ideas behind scripting languages are also relevant to more main-stream languages, such as Visual Basic.
There is a big danger lurking in all of this - the very simplicity of scripting languages makes them easy to overuse, and there is a new generation of users busy reinventing the mistakes of the previous generations, writing programs that no-one understands or can maintain.