
Из радиоприёмника на всю катушку гремела Битловская «We Can Work It Out» («Мы с этим справимся»), когда зазвонил телефон. Как только Пит (Pete) поднял трубку, телефон убавил громкость окружающих звуков, послав сообщение всем местным устройствам, имевшим регулятор громкости. Звонила его сестра Люси (Lucy) из кабинета врача: «Моей маме нужно попасть на приём к врачу, а потом ей требуется пройти несколько сеансов физиотерапии. Примерно два раза в неделю. Я сейчас поручу своему агенту записать нас на приём к врачу.» Пит сразу же согласился подвезти её маму на своей машине [share the chauffeuring].
|
|
| Рис. Miguel Salmeron |
Уже через несколько минут агент представил им план. Питу он не понравился — Университетская Клиника расположена на другой стороне города, и ему пришлось бы возвращаться обратно как раз в час пик. Он попросил своего агента повторить поиск с более строгими предпочтениями относительно места и времени. Тем временем агент Люси, полностью доверяя агенту Пита в рамках данной задачи, автоматически помогал, предоставляя тому права доступа и ссылки на уже добытую им информацию.
Практически мгновенно был предложен новый план: найденная клиника была уже гораздо ближе, и часы приёма более ранние, однако он содержал два предупреждения. Во-первых, Питу в данном случае нужно будет переназначить пару не очень важных встреч. Он взглянул, что это за встречи — и понял, что это не проблема. Второе замечание говорило о том, что в списке, предоставленном страховой компанией, данное учреждение не значилось как предоставляющее именно услуги физиотерапии: «Вид предоставляемых услуг и статус страховки были надёжно проверены другими способами», — успокаивал агент. — «(Подробнее?)»
Люси одобрила этот план почти в тот самый момент, когда Пит недовольно ворчал: «Отстань со своими подробностями!», и тем самым всё было улажено. (Конечно же, Пит не смог удержаться от подробностей и уже поздно вечером запросил у агента объяснений относительно того, каким же образом тот нашёл клинику, не значившуюся даже в соответствующих перечнях.)
Пит и Люси смогли воспользоваться своими агентами для решения всех этих задач благодаря не той Всемирной Сети (World Wide Web), которая существует на сегодняшний день, а Семантической Сети, в которую она эволюционирует завтра. Сейчас значительная часть содержания Сети предназначена для чтения человеком, а не для осмысленного манипулирования им с помощью компьютерных программ. Компьютер способен умело разобраться в разметке веб-страницы и произвести рутинную её обработку — тут идёт заголовок, здесь следует ссылка на другую страницу; но, вообще говоря, у компьютера нет надёжного способа обрабатывать семантику документа: это — домашняя страница физиотерапевтической клиники Хартмана и Штраусса, а эта ссылка ведёт на биографию доктора Хартмана.
Семантическая сеть привнесёт структуру в смысловое содержание веб-страниц, тем самым создав среду, в которой программные агенты, переходя со страницы на страницу, смогут без особого труда выполнять замысловатые запросы пользователей. Такой агент, зайдя на веб-страницу клиники, сможет узнать не только, что у этой страницы есть ключевые слова «лечение, медицина, физиотерапия» [в оригинале: «physical, therapy»] (их можно указывать уже сегодня), но также и то, что доктор Хартман работает в этой клинике по понедельникам, средам и пятницам, и что имеющийся на его сайте скрипт принимает на вход диапазон дат в формате гггг-мм-дд и возвращает назначенные часы приёма. И для того, чтобы всё это «знать», ему вовсе не обязательно обладать искусственным интеллектом наподобие компьютера HAL [персонаж фильма Артура Кларка и Стенли Кубрика «2001: A Space Odyssey» («2001: Космическая одиссея»), красноречивый и всеведущий компьютер; как говорит А.Кларк в одном из интервью, имя персонажа произошло от Heuristic Algorithmic — основаннный на эвристических алгоритмах. — Прим. и ссылки переводчика.] или робота C-3PO из фильма «Звёздные войны» [ссылки переводчика]. Вместо этого вся эта семантика будет заложена на веб-страницу в тот самый момент, когда офисный менеджер клиники (никогда не проходивший даже вводного курса по Computer Science) заполнял соответствующие поля форм, используя стандартное программное обеспечение для написания страниц Семантической Сети, а также ресурсы, имеющиеся на сайте Ассоциации Физиотерапии.
Семантическая сеть — это не какая-то отдельная сеть, а расширение уже существующей, такое что в ней информация снабжена точно определённым смыслом, позволяющим человеку и машине успешно взаимодействовать. И первые этапы на пути к «вплетению» Семантической Сети в структуру имеющейся Сети уже осуществляются полным ходом. В ближайшем будущем данные разработки возвестят о новых значительных функциональных возможностях, когда машины станут намного лучше обрабатывать и «понимать» те данные, которые сейчас они просто показывают на экране.
Существенным свойством Сети WWW является её универсальность. Вся мощь понятия гипертекста выражается следующими словами: «Bсё можно связать со всем». В виду этого сетевым технологиям не следует по-разному относиться к черновым наброскам страниц или же безупречно отточенным документам, к коммерческой или педагогической информации, а также к различным культурам, языкам, носителями информации и т.д. Информация бывает различного характера. Её можно разделить на предназначенную в первую очередь для человеческого восприятия и ту, что создана для машинной обработки. На одном конце этой шкалы — всё от рекламы на каком-нибудь канале ТВ до поэзии. На другом конце — базы данных, программы и сенсорные устройства вывода. До сих пор наиболее быстро Сеть развивалась именно как носитель документов для людей, а не информации и данных, допускающих автоматическую обработку. Семантическая же Сеть как раз имеет своей целью наверстать это упущение.
Подобно Интернету, Семантическая Сеть будет максимально децентрализована. Такие паутино-подобные [Web-like] системы предлагают массу удивительных возможностей всем, начиная от крупных компаний и заканчивая обычными пользователями, и дают такие преимущества, предсказать которые заранее трудно или даже невозможно. В то же время, децентрализация требует определённых компромиссов: существующей сейчас Сети пришлось отказаться от идеала полной согласованности всех её внутренних соединений, и в ней то и дело попадается пресловутая «Ошибка 404: Документ не найден», но за счёт этого стал возможен её беспрепятственный экспоненциальный рост.
Для того, чтобы Семантическая Сеть могла функционировать, компьютеры должны иметь доступ к структурированным хранилищам информации и множествам правил вывода, которые они могли бы использоваться для проведения автоматических рассуждений. Исследователи в области искусственного интеллекта занимались изучением подобных систем задолго до возникновения Сети. Представление знаний, как часто называют эту технологию, в настоящее время в состоянии, сравнимом с тем, каким было понятие гипертекста до появления Сети: идея, несомненно, здравая, и уже существуют достаточно хорошие опытные образцы [demonstrations], но пока ещё мир она не изменила. У неё уже есть зачатки важных приложений, но чтобы реализовать весь её потенциал, необходимо связать её в единую глобальную систему.

|
| Рис. Miguel Salmeron |
|
Сегодняшние поисковые системы зачастую выдают бесчисленное множество совершенно не относящихся к запросу «хитов», обрекая пользователя на длительный ручной отбор материала. Например, если вы ввели для поиска слово «cook», то компьютеру совершенно непонятно, имеете ли вы в виду повара, хотите ли найти информацию о рецептах приготовления пищи, или же вам нужно какое-то место, человек или компания или ещё что-либо, в чьём имени или названии встречается слово «cook». Вся проблема в том, что для компьютера слово «cook» не имеет чёткого смысла, или другими словами, семантического содержания. |
Традиционные системы представления знаний зачастую были централизованными, требуя, чтобы все использовали в точности одни и те же определения общих понятий, как то «родитель» или «автомобиль». Но подобный контроль является слишком сдерживающим, и по мере роста размеров и масштабов такой системы она достаточно быстро становится неконтролируемой.
Более того, в таких системах обычно предусмотрительно ограничивают круг тех вопросов, которые можно ей задать, с тем, чтобы компьютер был в состоянии дать на них достоверный (или хотя бы какой-нибудь) ответ. Эта проблема очень напоминает теорему Гёделя из математики: всякая система, достаточно сложная, чтобы быть сколь-нибудь полезной, обязательно содержит вопросы, на которые в принципе невозможно дать ответ; последние очень похожи на усложнённые [sophisticated] версии простейшего парадокса: «Это предложение ложно». Чтобы избежать подобных проблем, всякая традиционная система представления знаний, как правило, старается ограничиться достаточно узким и характерным для неё [idiosyncratic] набором правил для построения выводов из имеющихся у них данных. Так например, генеалогическая система, работающая с базой данных родословных, может включать в себя такое правило: «жена дяди есть тётя». При этом даже если данные и можно было бы перенести из одной системы в другую, то правила, которые сами по себе существуют в совершенно другом нежели данные виде, уже обычно перенести не удаётся.
Исследователи же в области Семантичекой Сети, напротив, допускают такие парадоксы и вопросы, не имеющие ответа, как цену за достижение гибкости [versatility]. Язык, на котором предполагается формулировать правила вывода, изначально создаётся настолько выразительным, чтобы позволять Сети пользоваться рассуждениями как можно шире. Философия здесь сходна с той, что применяется в обычной Сети: ещё на заре её развития скептики [detractors] указывали на то, что она никогда не сможет стать чётко организованной библиотекой; а не имея централизованной базы данных и структуры в виде дерева, невозможно быть уверенным, что в ней вообще что-то можно будет отыскать. И они были правы. Однако выразительная сила этой системы сделала вполне доступным гигантское количество информации, и поисковые службы (которые казались почти неосуществимыми всего какой-то десяток лет назад) сейчас предлагают нам удивительно полные каталоги огромного количества материала по всей сети. Таким образом, цель [challenge] Семантической Сети — создать язык, на котором можно будет описывать как данные, так и правила рассуждений об этих данных, так чтобы он позволял правила вывода, существующие в какой-либо одной системе представления знаний, передавать по Сети другим подобным системам.
Привнести в Сеть логику (как то: способы применения правил вывода для проведения рассуждений, методы выбора тактик выполнения операций с данными и средства для ответов на вопросы) — вот та задача, которая стоит перед сообществом Семантической Сети в настоящий момент. Комбинирование [mixture] существующих математических и инженерных решений усложняет эту задачу. Эта логика должна быть, с одной стороны, достаточно сильной, чтобы позволять описывать сложные свойства объектов, а с другой — не на столько сильной, чтобы агента можно было поставить в тупик, дав ему парадоксальный запрос. К счастью, подавляющее большинство информации, которую мы хотим выразить, представляет собой нечто вроде «шестигранный болт является типом машинных болтов», что без труда вписывается в уже существующие языки, расширенные некоторыми дополнительными языковыми конструкциями [vocabulary].
Сейчас уже созданы две важные технологии для развития Семантической Сети: Расширяемый Язык Разметки (eXtensible Markup Language, XML) и Система Описания Ресурсов (Resource Description Framework, RDF). [Прим. перев.: на момент перевода статьи уже появился Язык Сетевых Онтологий (Web Ontology Language, OWL, русский перевод документа здесь), которому 10 февраля 2004 года WWW-Консорциум (W3C) присвоил статус рекомендованной к реализации технологии. Некоторые уже предлагают считать эту дату официальным днём рождения Семантической сети.] Язык XML позволяет создавать свои собственные тэги — скрытые метки типа <zip code> [почтовый индекс — Прим.перев.] или <alma mater> [оконченный университет или колледж — Прим.перев.], которыми можно снабжать веб-страницы или разделы текста на страницах. Скрипты и программы могут использовать эти тэги самым замысловатым образом, но при этом программист, пишущий эти скрипты, должен знать, для чего автором веб-страницы используется тот или иной тэг. Короче говоря, язык XML даёт возможность пользователям снабжать свои документы произвольной структурой, однако данный язык ничего не говорит о том, что означает эта структура.
|
Семантическая сеть позволит машинам ПОНИМАТЬ семантику документов и данных, но не человеческую речь или его сочинения. |
Смысл выражается посредством языка RDF, который кодирует его с помощью множества триплетов [triple], где каждый триплет состоит из субъекта, глагола и объекта элементарного предложения. Такие триплеты можно записать с помощью тэгов языка XML. В языке RDF документ состоит из утверждений о том, что нечто (человек, веб-страница или что-либо ещё) имеет определённое отношение (как то «быть сестрой», «быть автором») с некоторым определённым значением (другой человек, другая веб-страница). Подобная структура оказывается весьма естественной для описания подавляющего большинства машинно-обрабатываемых данных. Субъект и объект задаются с помощью Единообразного Идентификатора Ресурса (Uniform Resource Identifier, URI), подобно ссылкам на веб-страницах. (URL — Универсальный Локатор Ресурса (Universal Resource Locator) — представляет собой наиболее распространённый тип URI). Глаголы тоже задаются посредством URI, что позволяет определять новое понятие или новый глагол, просто указав его URI-адрес в Сети.
Человеческий язык процветает благодаря тому, что одно и тоже слово может иметь несколько значений; но это совсем не так для языка машинного. Представьте себе, например, что я нанимаю клоунов-курьеров для доставки воздушных шариков моим клиентам на их дни рождения. Совершенно не кстати, эта развлекательная служба перекачает мою базу данных с адресами клиентов себе, не зная, что «адрес» в моей базе данных — это то место, куда доставляются счета, и что большинство из них — абонентские ящики в почтовых отделениях. В итоге мои клоуны повеселят почтовых работников — что само по себе, возможно, не так уж и плохо, но, очевидно, это не то, чего хотелось изначально. Подобная проблема решается использованием различных URI для каждого конкретного понятия. Почтовый адрес тогда можно будет отличить от адреса проживания, и оба эти понятия, в свою очередь, можно будет отличить от понятия «адресовать речь кому-либо» [an address that is a speech].
Из триплетов языка RDF формируются сети информации о взаимосвязанных вещах. Поскольку RDF использует URI-идентификаторы для кодирования данной информации в документе, эти самые URI-идентификаторы гарантируют то, что каждое понятие, используемое в документе — это не просто слово, а нечто, привязанное к единому определению, которое каждый желающий может найти в Сети. Например, представим себе, что у нас есть доступ к нескольким базам данных о людях, содержащим их адреса. Если теперь мы хотим найти тех людей, которые живут в районе с неким заданным почтовым индексом, то нам нужно будет знать, какое именно поле в каждой из баз данных представляет собой имя, а какой — почтовый индекс. Это можно выразить на языке RDF в виде: «(поле 5 в базе данных A)(является полем типа)(почтовый индекс)», используя URI-идентификаторы вместо слов для каждого термина.
Разумеется, наша история ещё не закончена, поскольку две базы данных могут использовать различные идентификаторы для обозначения одного и того же понятия, такого как почтовый индекс. И программа, желающая сравнить или как-то скомбинировать информацию из этих баз данных, должна знать, что два конкретных термина используются ими для обозначения одного и того же. В идеале, у программы должен быть способ распознавать подобные термины с одинаковым смыслом, с какими бы базами данных ей не пришлось столкнуться в процессе своей работы.
Решение этой проблемы даётся третим базовым компонентом Семантической Сети — совокупностью информации, которое специалисты именуют онтологией. В философии онтологией называют некую теорию о природе бытия, о видах сущностей; есть также раздел философии — онтология — в котором изучаются подобные теории. Наука об «искусственном интеллекте» и исследователи в области сетевых технологий заимствовали этот термин в свой лексикон, и для них уже онтология — это документ или файл, формально задающий отношения между терминами. Наиболее типичными видами онтологий в Сети являются таксономия и набор правил вывода.
Таксономия определяет классы объектов и отношения между ними. Например, понятие адрес может быть определено как разновидность понятия местонахождение [location], а код города можно задавать применительно лишь к местонахождениям и так далее. Задание классов, подклассов, а также отношений между индивидами [entities] является чрезвычайно мощным инструментом для использования в Сети. Большое количество отношений между индивидами можно задать путём приписывания классам определённых свойств и позволяя подклассам наследовать эти свойства. Если, скажем, код города есть свойство объектов типа город, а в свою очередь, города, в большинстве своём, имеют собственные веб-сайты, то мы можем говорить, что некий веб-сайт связан с определённым кодом города, хотя в нашей базе и нет прямой связи, ведущей от кода города к веб-сайту.
Правила вывода, задаваемые в онтологиях, дают ещё больше возможностей. В рамках онтологии можно записать такое правило: «Если код города соответствует некоторому коду штата, а в адресе фигурирует код города, то этому адресу тоже соответствует тот же самый код штата». В этих условиях программа может без труда вывести, например, что коль скоро Корнелльский Университет находится в г. Итака, который расположен в штате Нью-Йорк, который, в свою очередь, есть часть США, то адрес этого университета следует писать в американском формате. Компьютер не «понимает» в полном смысле этого слова ничего из всей этой информации, но теперь он уже может манипулировать терминами гораздо более эффективно с тем, чтобы стать полезным и осмысленным для пользователя-человека.
Как только доступные всем онтологии появятся в Сети, описанные нами терминологические (и другие) проблемы обретут своё решение. Смысл каждого термина или XML-кода, использованного на веб-странице, можно будет задать посредством указателя с этой страницы на соответствующую онтологию. Конечно же, тут возникает та же самая проблема, что и упомянутая выше, когда я ссылаюсь на одну онтологию, в которой определено понятие адреса, включающего в себя понятие zip-кода [синоним термина «почтовый индекс» в англ. яз. — Прим.перев.], а Вы ссылаетесь на другую онтологию, оперирующую уже термином почтовый индекс. Однако такого рода путаницу можно устранить, если онтологии (или же какие-то другие веб-сервисы) позволяют задавать отношение эквивалентности: в одну или же в обе наши онтологии можно поместить информацию о том, что понятие zip-кода эквивалентно понятию почтового индекса.
Наша загвоздка с посылкой клоунов для развлечения моих клиентов частично будет устранена, если две упомянутые в ней базы данных будут ссылаться на разные определения термина адрес. Программа, используя различные URI-идентификаторы для этих различных понятий адреса, уже не будет их путать, и на самом деле даже обнаружит, что эти два понятия почти не связаны друг с другом. Далее программа может воспользоваться неким сервисом, позволяющим взять список почтовых адресов (термин из одной онтологии) и преобразовать его в список физических адресов (термин второй онтологии), распознав и выбросив из него абонентские ящики и другие неподходящие для наших целей адреса. Таким образом, структура и семантика, задаваемые в онтологиях, позволяют предпринимателю предоставлять подобные услуги и делать их чрезвычайно прозрачным в использовании.
Онтологии способны улучшить функциональность Сети во многих аспектах. В простейшем случае, их можно использовать для увеличения точности поиска в Сети — поисковая машина будет выдавать только такие сайты, где упоминается в точности искомое понятие, а не произвольные страницы, в тексте которых встретилось данное многозначное ключевое слово. Более продвинутые приложения будут использовать онтологии, чтобы соотнести информацию на странице со связанной с ней структурой знаний и правилами вывода. Пример страницы, размеченной для такого использования, уже есть в сети по адресу http://www.cs.umd.edu/~hendler [страница одного из авторов статьи — Прим.перев.]. Открыв эту страницу с помощью веб-браузера, вы увидете самую обычную страницу, с заголовком «Dr. James A. Hendler». Вы легко, с точки зрения человека, найдёте там ссылку на краткий биогафический очерк, где прочтёте, что Хендлер получил степень Доктора Философии [Ph.D.] в Браунском [Brawn] Университете. Однако, если же эту информацию попытается найти компьютерная программа, то ей будет чрезвычайно сложно догадаться, что эта информация является биографией, и понять написанный там текст на английском языке.
Именно по этой причине для компьютерного восприятия данная страница снабжена ссылками на онтологическую страницу, задающую информацию о факультете Computer Science. На ней, в частности, говорится, что профессора работают в университете и что они обычно имеют докторскую степень. Далее разметка (не отображающаяся на дисплее стандартным веб-браузером) на странице Хендлера, используя понятия этой же онтологии, сообщает, что Хендлер получил степень Доктора Философии в организации, описанной по URI-адресу http://www.brown.edu, который является адресом веб-страницы Браунского Университета. Компьютер также может найти на этой странице информацию о том, что Хендлер является участником определённого исследовательского проекта, у него есть определённый e-mail-адрес и так далее. Вся эта информация может быть без особого труда обработана компьютером и использована для ответов на различные запросы (как то: где доктор Хендлер получил учёную степень?), тогда как сейчас для этого требуется, чтобы человек внимательно ознакомился с содержанием нескольких страниц, которые выдала поисковая система.
Кроме того, подобная разметка делает гораздо проще разработку программ, которые будут способны обрабатывать более сложные вопросы, ответы на которые не содержатся на какой-то одной веб-странице. Предположим, Вы хотите найти некую госпожу Кук [Ms. Cook], с которой Вы познакомились на профсоюзной конференции в прошлом году. Вы не помните её имени, однако помните, что она работала в какой-то компании, которая является Вашим клиентом, и что её сын учится в том же университете [alma mater], который окончили Вы. Умная поисковая система просканирует все страницы людей с фамилией Кук (при этом пропуская страницы о поварах [cooks], приготовлении пищи [cooking], Кукских островах [Cook Islands] и т.п.), выберет среди них те, на которых упоминаемый человек работает в компании, входящей в список Ваших клиентов, а также пробежит по ссылкам на веб-страницы учебных заведений, в которых учатся их дети, чтобы проверить, не тот ли самый это университет.
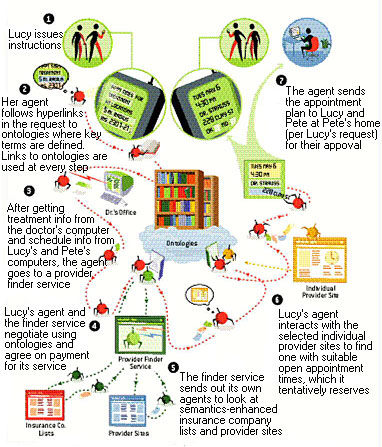
|
| Рис. Miguel Salmeron |
|
Семантическое наполнение сети будет очень способствовать работе программных агентов. На изображённом тут сценарии агент Люси разыскивает физиотерапевтическую клинику для её мамы, удовлетворяющую комбинации заданных критериев, в которой часы приёма врачей стыкуются с расписанием Люси и её брата Пита. Онтологии, задающие смысл семантических данных, играют здесь ключевую, давая возможность агентам понимать, что содержится в Семантической Сети, взаимодействовать с сайтами и другими автоматизированными сервисами. |
В полную силу Семантическая Сеть будет реализована тогда, когда люди создадут множество программ, которые, знакомясь с содержимым Сети из различных источников, обрабатывают полученную информацию и обмениваются результатами с другими программами. Эффективность таких программных агентов будет расти экспоненциально по мере увеличения количества доступного машинно-воспринимаемого веб-контента и автоматизированных сервисов (включая других агентов). Семантическая Сеть стимулирует подобного рода совместную деятельность [synergy]: даже те агенты, которые не были созданы специально для работы сообща, могут передавать информацию между собой, коль скоро эта информация будет снабжена семантикой.
Важным аспектом функционирования агентов будет возможность обмена «доказательствами», записанными в унифицированном языке Семантической Сети (языке, на котором можно записывать логические рассуждения, проведенные с использованием содержащейся в онтологиях информации и правил вывода). Предположим, например, что некий онлайн-сервис нашёл контактную информацию госпожи Кук и к Вашему удивлению утверждает, что она находится в Йоханнесбурге. Естественно, Вам захочется это проверить, и Ваш компьютер запросит у агента доказательство правильности его ответа, которое тот немедленно сможет предоставить, переведя внутренние проведённые им рассуждения на унифицированный язык Семантической Сети. Программа на Вашем компьютере, специализирующаяся на проверке правильности логических выводов, легко подтвердит, что эта г-жа Кук действительно удовлетворяет заданным Вами критериям поиска, и более того, будет готова показать Вам соответствующие веб-страницы, если у Вас всё же остались сомнения. Некоторые программы уже сейчас могут обмениваться доказательствами подобным образом, используя имеющиеся сейчас предварительные версии унифицированного языка, однако пока рано говорить о том, что они способны понять и использовать весь потенциал Семантической Сети.
Другой жизненно важной функциональностью будут цифровые подписи, представляющие собой зашифрованные блоки данных, которые могут использоваться компьютерами и агентами для проверки того, что полученная информация предоставлена известным надёжным источником. Всегда хочется быть уверенным, что платёжное требование, посланное программе, управляющей Вашим счётом, по которому Вы собираетесь перечислить деньги интернет-магазину, — не какая-то фальшивка, сделанная смышлённым мальчуганом из соседней квартиры. Агенты не должы быть слишком доверчивым к утверждениям, прочитанным ими в недрах Семантической Сети, до тех пор, пока они не убедятся в достоверности источника информации. (Надеемся, что всё больше людей тоже научатся этому, бродя по просторам Сети!)
В настоящее время уже существует множество автоматизированных веб-сервисов безо всякой семантики, однако другим программам, таким как агенты, нет никакого способа разыскать в сети подобную программу, выполняющую ту или иную функцию. Этот процесс, называемый обнаружением сервисов [service discovery], станет возможным лишь после того, как появится единый язык, позволяющий описывать сервисы, с тем чтобы агенты могли «понимать», что позволяет делать данный сервис и каким образом им пользоваться. Сервисы и агенты могут рекламировать выполняемые ими функции, например, занося подобные описания в справочники, подобные Жёлтым Страницам. [Прим. перев.: На момент перевода этой статьи подобный язык описания сервисов — Язык Онтологии Сетевых Сервисов (Web Services Ontology Language, OWL-S) — уже находится в стадии разработки WWW-Консорциумом (W3C); последняя его версия (1.1, бета) была выпущена в июле 2004 г.]
Некоторые схемы нижнего уровня для обнаружения сервисов уже доступны сейчас, как то Universal Plug and Play фирмы Microsoft [автоматическое распознавание и настройка периферийного устройства без последующей установки параметров пользователем — Прим.перев.], которая занимается проблемой подключениия друг к другу различных типов устройств; система Jini компании Sun Microsystems, предназначенная для соединения сервисов друг с другом. Однако, подобная деятельность направлена на решение проблем на структурном или синтаксическом уровне и в значительной степени основывается на стандартитизации описаний предопределённого набора функций. Конечно же, стандартизация может существовать лишь до определённого момента, поскольку нельзя заранее предусмотреть все возможные потребности будущего.
|
Правильно организованная Семантическая Cеть может способствовать эволюции человеческого знания в целом. |
Любой типичный процесс будет включать в себя создание «цепочки прироста стоимости» [«value chain»], в которой фрагменты информации передаются от одного агента к другому, каждый раз наращивая свою ценность [value], приводя в конечном счёте к пострению окончательного результата, запрошенного конечным пользователем. Дабы избежать возможных заблуждений, подчеркнём: чтобы создавать подобные сложные цепочки автоматически по запросу, некоторым агентам не обойтись без технологий из области искусственного интеллекта в дополнение к Семантической Сети. Но именно Семантическая Сеть предоставит фундамент и среду [framework] для того, чтобы подобные технологии стали более осуществимыми.
Комбинирование всех перечисленных типов функциональности [features] приведёт в конечном итоге к возможностям, продемонстрированным агентами Пита и Люси в сценарии, с которого мы начали эту статью. Эти агенты поручали части задач другим агентам и сервисам, найденным ими в справочниках, рекламирующих данные услуги. К примеру, они смогли воспользоваться надёжным сервисом, чтобы получить перечень мед. учреждений, и затем выбрать из них те, которые соответствуют определённой страховке [insurance plan] и курсу лечения. Сам этот перечень мед. учреждений, в свою очередь, был предоставлен другим поисковым сервисом, и так далее. Вся эта деятельность выстроилась в цепочки, в которых большой объём разбросанных по Сети данных (значительная часть которых сама по себе мало значима для поставленной задачи) постепенно сводился к небольшому количеству информации, имеющему огромное значение для Пита и Люси — а именно, к назначенным часам приёма врачей, соответствующих их расписаниям и другим требованиям.
На следующем этапе Семантическая Сеть уже вырвется из виртуальной области и расширит сферу своего влияния на наш физический мир. Поскольку URI-идентификаторы могут указывать на что угодно, в частности, и на физические объекты, это означает, что язык RDF можно использовать для описания устройств, таких как сотовый телефон или телевизор. Эти устройства могут рекламировать свои функциональные возможности — то есть что они умеют делать и каким образом ими можно управлять — практически так же, как это делают программные агенты. Будучи гораздо более гибким по сравнению со схемами низкого уровня наподобие Universal Plug and Play, данный семантический подход открывает мир потрясающих возможностей.
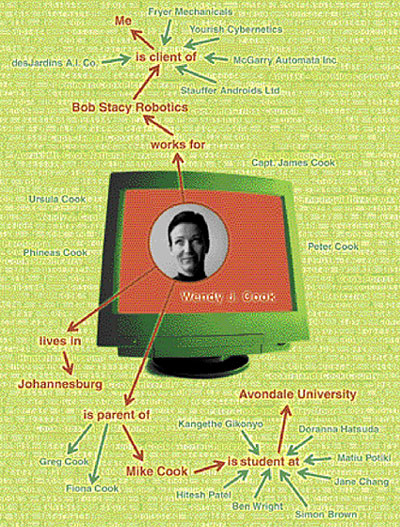
|
| Рис. Miguel Salmeron |
|
СОВЕРШЕННЫЕ и ТОЧНЫЕ АВТОМАТИЗИРОВАННЫЕ поисковые системы станут возможны, когда Сеть наполнится семантикой. На рисунке поисковая программа безошибочно отыскивает человека, основываясь на наборе частично припомненных знаниях: её фамилия «Кук», она работает в компании, входящей в список Ваших клиентов, и у неё есть сын, учащийся в том же университете, который окончили Вы (Avondale University). Правильной комбинации нужной информации нет ни на одном отдельно взятом веб-сайте, однако благодаря семантике программа достаточно легко распознала отдельные элементы этой информации на различных веб-страницах, поняла отношения между ними, как то «Майк Кук является сыном Уэнди Кук» и правильно составила из этих частей единое целое. В общем случае, семантика позволит автоматически проводить сложные процессы и трансакции. |
Например, так называемая домашняя автоматизация требует сейчас тщательной настройки всех устройств для их совместной работы. Семантическое же описание возможностей и порядка функционирования этих устройств позволит достичь той же автоматизации, но уже с минимальным вмешательством человека. В качестве простейшего примера можно вспомнить, как Пит ответил на телефонный звонок и при этом громкость окружающих звуков убавилась. Вместо того, чтобы программировать каждое из отдельных устройств, он запрограммировал эту функцию раз и навсегда, чтобы она сказывалась на работе всех местных устройств, которые указали в своей рекламе наличие у них регулятора громкости — будь то телевизор, DVD-плеер или даже медиаплеер, установленный на его портативном компьютере, который он принёс в тот вечер домой.
Первые конкретные шаги на этом пути уже сделаны, параллельно с разработкой стандартов для описания функциональных возможностей устройств (как то размеры экрана) и пользовательских предпочтений. Эти стандарты, основанные на языке RDF, называются Составные Профили Возможностей/Предпочтений (Composite Capability/Preference Profile, CC/PP). [См. также русскоязычный комментарий — Прим.перев.]. Поначалу данный стандарт будет позволять сотовым телефонам и другим нестандартным веб-браузерам предоставлять свои характеристики с тем, чтобы содержание веб-страниц на лету переформатировалось для них. Позже, когда у нас уже появится всё многообразие языков для оперирования онтологиями и логикой, устройства смогут сами отыскивать и запускать нужные им сервисы и другие устройства для получения дополнительной информации или расширения своей функциональности. Уже совсем не трудно вообразить, как ваша микроволновая печь, снабженная Сетевым доступом, будет консультироваться на веб-сайте производителя замороженных продуктов об оптимальных параметрах их приготовления.
Семантическая сеть — это не «просто» инструмент для решения чьих-то индивидуальных задач, обсуждавшихся нами до сих пор. Правильно организованная Семантическая Cеть может, помимо прочего, способствовать эволюции человеческого знания в целом.
Человеческие усилия стеснены вечным противоречием между эффективностью малых независимо действующих групп людей и необходимостью согласования своих действий с широкой общественностью. Небольшой коллектив может быстро и эффективно создать нечто новое, однако зачастую это порождает своего рода субкультуру, концепции которой могут быть не поняты окружающими. С другой стороны, координирование действий большой группы чрезвычайно замедляет процессы и требует колоссального количества общений. Всё в мире работает где-то посредине между двумя этими крайностями, с преобладанием тенденции начинать с малого — некой частной идеи — и постепенно продвигаться на пути к более широкому пониманию.
Существенным процессом становится объединение субкультур, когда требуется более широкий единый язык. Очень часто две независимо работающие группы разрабатывают очень сходные концепции, и попытка описать взаимосвязи между этими концепциями даст весьма существенную выгоду. Подобно финско-английскому языку или таблице преобразования мер и весов, эти взаимосвязи позволят общаться и сотрудничать, даже когда общность понятий не перешла (пока ещё) в общность терминов.
Семантическая Сеть, именуя всякое понятие просто с помощью URI-идентификатора, даст возможность каждому выражать новые понятия, которые он изобретает, с минимальными усилиями. Её универсальный логический язык позволит постепенно связать все эти понятия в универсальную Сеть. Эта структура сделает знания и достижения человечества доступными для анализа программными агентами и предложит нам новый класс средств, с помощью которых мы можем вместе жить, работать и учиться.
До настоящего времени Всемирная Компьютерная Сеть (WWW) наиболее быстро развивалась как носитель документов, используемых людьми, а не как хранилище информации, допускающей автоматическую обработку. Снабдив веб-страницы некоторым количеством компьютерно-ориентированных данных, а также создав документы, предназначенные исключительно для компьютеров, мы тем самым превратим эту Сеть в Семантическую Сеть.
Компьютеры смогут понимать смысл семантических данных, следуя по гиперссылкам, ведущим к определениям ключевых терминов и правилам логических рассуждений о них. Полученная в результате инфраструктура даст отправную точку для разработки автоматизированных веб-сервисов, таких как высоко функциональные агенты.
Cоздавать страницы Семантической Сети смогут обычные пользователи, равно как давать собственные определения и вводить новые правила вывода, используя стандартное программное обеспечение, поставляемое для работы с семантической разметкой.
После того, как мы рассказываем о Семантической Сети, нам часто задают вопрос: «Это всё замечательно. А скажите, что же станет ключевой программой-приманкой Семантической Сети?» Под программой- или приложением-приманкой [killer application] какой-либо технологии, очевидно, здесь следут понимать приложение, которое привлечёт новых клиентов к изучению этой технологии и последующему её использованию. Так например, транзисторное радио было приложением-приманкой для технологии транзисторов, а сотовый телефон — для беспроводных технологий.
Итак, что же нам ответить? «Семантическая Сеть сама по себе является приложением-приманкой!»
После такого ответа, вполне вероятно, нам скажут, что мы сумасшедшие, но мы в ответ зададим уже свой вопрос: «Тогда скажите вы нам, а что является программой-приманкой Всемирной Компьютерной Сети WWW?» Теперь уже на нас смотрят недоумевающими глазами, а мы сами сами даём ответ: «Сеть WWW сама является программой-приманкой для [технологии под названием] Интернет. Семантическая же сеть — ещё одно приложение-приманка для того же самого.»
Всё дело в том, что возможности Семантической Сети чрезвычайно широки для того, чтобы о ней можно было говорить в терминах решения какой-то одной частной ключевой проблемы или создания на её основе какого-то одного существенного приложения [gizmo]. Её можно будет использовать в таких аспектах, о которых мы даже и не подозревали.
Тем не менее, уже сейчас мы можем предвидеть некоторые обескураживающие [disarming] (если не на самом деле убийственные [killer]) приложения, которые сразу же найдут своего пользователя. Онлайн-каталоги, снабжённые семантической разметкой, принесут немалую пользу как покупателям, так и продавцам. В сфере малого бизнеса станет гораздо проще налаживать проведение трансакций в области электронной коммерции, имеющих большую степень защиты и автоматизации. И последний пример: допустим, вы заранее бронируете места с целью совершения длительной зарубежной поездки. Аэропорты, гостиницы, футбольные стадионы и проч. подтверждают бронирование требуемых мест, пользуясь семантической разметкой. После этого расписание всех намеченных событий и поездок загружается в ваш ежедневник, а все планируемые расходы — в программу, управляющую Вашим счётом, причём совершенно не имеет значения, какое семантически настроенное программное обеспечение Вами используется. Больше не нужно сидеть за утомительным занятием перенесения нужной информации из электронных писем. Больше не требуется для различных видов деятельности пользоваться пол-дюжиной различных форматов данных, или более того, для каждого нового вида деятельности самому разрабатывать и внедрять новые форматы.
{kind=link}