SPARQLing Queries
Bijan Parsia
The University of Manchester
The (HTML) Web
- (Rough) Definition
- Static: A set of interlinked HTML documents accessible via HTTP
- Dynamic: A set of programs which generate HTML documents in response to HTTP requests
- HTML is a human oriented format (by
design and evolution)
- Lots of presentation features
- Few structural tags that are fairly generic (
<em>) or systematically misused (<blockquote>)
- Lots of databases use HTML as a (thin
client) interface
- And many (most?) Websites are database backed
Querying the (HTML) Web
- The four classic modes:
- The browser "find" command
- Web site specific search engine
- Ranges from mere text searching to database front end
- Custom edited portals (e.g., Old Yahoo!)
- Tags/categories
- Search engines (i.e., Google
- Text + document structure + large scale link structure
- Problems:
- Heavy reliance on text, presentation, and untyped links
- Underlying information structure is, at best, implicit in the rendering, and often not exposed at all
The (XML) Web
- (Rough) definition
- A set of static or dynamic XML documents accessible via HTTP
- (Web Services) A set of endpoints that respond to XML messages with XML messages and are described by XML documents
- A tension
- Document orientation
- Data orientation
- Semi-structured data
- Between RDBMS and plain text/HTML
- Flexible structure (e.g., post hoc validation) and retrieval
Querying the (XML) Web
- For documents:
- Not much has changed (e.g., XHTML)
- Metadata perhaps more accessible/likely
- For data:
- Generic
- XPath
- XQuery
- Application specific
- UDDI (perhaps)
- RDF (technically)
- No (XML specific) Generic Search engines
- Can't perform an XPath query across most of the Web
The Semantic Web
- (Very rough) definition
- A set of interlinked (in some way) KRs
- A set of KRs using URIs as identifiers
- A set of RDF/XML documents
- expressing anything from RDF to OWL
- (We'll stick with the most specific definition)
- RDF(S)
- A novel, slightly weird, weak semantic net language
- OWL DL
- A variant of the Description Logic SHOIN(D)
- OWL Full
- RDFS + OWL DL + the kitchen sink
Querying the Semantic Web
- Web engine search
- Keyword/filetype sensitive (e.g., Google)
- Bit of structure (e.g., Swoogle)
- Parasitic off of Google
- Defines an "OntologyRank" measure
- Kind of search
- Lexical
- Simple semantics based
- retrieve instances of a class
- retrieve types of an instance
- "Arbitrary" conjunctive query
- All ?x, ?y such that ?x loves ?y and ?y loves ?z
q(?x,?y) :-loves(?x,?y),loves(?y,?z)
SPARQL
- SPARQL Protocol And RDF Query Language
- Product of the Data Access Working Group (DAWG)
- 4 core specs
- Spec 1 is very much in flux
- 2 describes a very minimal protocol (query only)
- Both HTTP and SOAP bindings
- In this tutorial, we will focus on 1; hereafter:
- "SPARQL" is used for "SPARQL Query Language"
- (We will have much to say about "for RDF")
Desiderata (1)
- Semantically well-specified
- Related to the queried formalism
- Clear and unambiguous
- Complete (cover all corner cases)
- Closed (thus freely compositional)
- Sensible metalogical properties
- Usable
- Syntax and constructs should be usable
- Sufficient expressivity for applications
- Results should not mislead
- Implementable
- Preferably without too much change to existing systems and techniques
Desiderata (2)
- Modular semantics
- Core
- There are (at least) 6 semantics for RDF graphs:
- Simple/RDF/RDFS + datatype variants
- OWL Lite/DL/Full
- With non-obvious relationships
- Algebra
- Manipulation of tables
- Should be (largely) independent of core
- Tension with closure
- Predicable answers
- Various syntaxes
- Directly human usable; familiar to SQL users
- XML syntax (for interchange and Web services)
RDF Syntax (Turtle)
- RDF Terms:
- URIs as identifiers for individuals, properties, classes, and datatypes
<http://ex.org>,dc:creator- BNodes
_:x,[]- Literal (three kinds)
- Plain literals (with and without a lang tag)
"Bom dia","2006-09-04""Bom dia"@pt- Typed literals
"2006-09-04"^^xsd:date,"Bom dia"^^xsd:string- RDF triples:
- <URI or BNode> <URI> <URI, BNode, or Literal> .
Example Turtle
@prefix rdf:
<http://www.w3.org/1999/02/22-rdf-syntax-ns#>.
@prefix xsd:
<http://www.w3.org/2001/XMLSchema#>.
@prefix : <http://www.ex.org/>.
:mary
rdf:type <http://www.ex.org/Gardener>.
:mary :worksFor :ElJardinHaus.
:mary :idNumber
"12345"^^xsd:integer.
:mary :name "Dalileh
Jones"@en.
_:john :worksFor :ElJardinHas.
_:john :idNumber "54321"^^xsd:integer.
RDF Semantics
- RDF(S) and OWL have model theoretic semantics
- RDF has several flavors of interpretation function
- Simple
- The "pure graph" semantics
- RDF
- New "logical" vocabulary
- Limited form of rdf:type
- rdf:Property (only class)
- rdf:XMLLiteral (only datatype)
- Trivial axiomatic triples, plus other vocab
- RDFS
- More "logical" vocabulary
- Datatypes (via an extension)
- Possibility for (very limited) contradiction
Simple Interpretations
- Domain IR (non-empty set of "resources") with subset:
- LV, the set of plain literals
- IP, the set of properties
- Mapping functions:
- IS: URI → IP + IR
- IEXT: IP → IR × IR
- IL: Typed Literals → IR
- A: Blank nodes → IR
- Simple interpretation: Is(<s, p, o>):
- True if Is(p) in IP, <Is(s), Is(o)> in IEXT(I(p))
- True if Is(p) in IP, <A(s), Is(o)> in IEXT(I(p)) for some A
- (Same for other cases)
- False otherwise
RDF(D) Interpretations
- Two interesting bits (only one for SPARQL)
- p in IP iff <p, I(rdf:Property)> in IEXT(rdf:type)
- Typed literals
- Add the notion of well and ill-formed literals
- Well-formed literals → value space of the type
- Ill-formed literals → disjoint from value space
- Potential for contradiction!
- Not expressible in plain RDF
- Only one built in type: rdf:XMLLiteral
- No way to get something in and out of the value space
- Possible with additional, disjoint types
- _:x rdf:type xsd:positiveInteger.
- _:x rdf:type xsd:negativeInteger.
What is a Query?
- A query is a question
- Answering requires understanding
- The query
- The thing queried
- The relationship between them
- The results
- The relationship is usually entailment
- KB ⇒ Q
- If there are no reported variables, the query is boolean
- We can reduce queries with reported variables to boolean queries
- Not everything is so easy
- Counting, aggregation, disjunction, etc.
RDF Graphs as Queries
- Ground graphs as queries
- Boolean query only
- "Yes" if data graph ⇒ query graph
- BNodes as query variables
- There is an answer if data graph ⇒ query graph
- We can get bindings by replacing the BNodes with a substitution and checking whether the new query graph is entailed by the data graph
- The substitution can, perhaps, contain BNodes
- Efficient implementation is, obviously, more complex
Graph Patterns
- Why generalize on RDF graphs?
- Variables in predicate position
- Syntactic distinctness
- Lexical robustness
SELECT ?x WHERE {?x :loves ?y. ?y :loves _:z}q(?x) :- loves(?x, ?y), loves(?y, _:z).
Graph Patterns
- Why generalize on RDF graphs?
- Variables in predicate position
- Syntactic distinctness
- Lexical robustness
SELECT ?x WHERE {?x :loves ?y. ?y :loves _:z}q(?x) :- loves(?x, ?y), loves(?y, _:z).- Head
- Body
- A body that is an RDF graph + (perhaps) query variables is a Basic Graph Pattern (BGP)
BGPs and Tables
- A BGP matching operation results in a table
- Not a graph
- Thus, you cannot compose BGPs
- Thus, SPARQL is not closed
- Current thinking: Two phases
- BGP "extracts" tables from the data
- Algebraic operators work on tables
- Preferably the two phases are independent
- Conceptually, at least
Variables and Bindings
- 2 key properties of a variable with 4 combinations
-
In head of query Binds to
names onlyA. Yes/Yes C. Yes/No B. No/Yes D. No/No - Distinguished
- "Semi-"distinguished
- "Projected away" distinguished
- Non-distinguished
- In a relational/Datalog setting, only A and C are possible
- C and D collapse (no non-named entities)
- In description logic settings, A and D are standard
- SPARQL "introduces" B
Considerations
- Distinguished, or projected away distinguished are easiest
- Bind only to names
- Reduces SPARQL over RDF to relational (mostly)
- Tables don't contain variables (no scope/duplicate issues)
- Lean vs. non-lean source graphs don't matter
- Miss answers
- Non-distinguished
- Basic answering can be more difficult (esp. in DL)
- But tables and algebra remain the same
- Miss co-reference of answers
- Semi-distinguished
- Basic answering can be more difficult
- New issues for the algebra and final results
(Non-)Distinguished example
- Data:
:bob :loves _:x._:x :loves :bob._:y :loves :sally:sally :loves :sheevah.
| SELECT ?lover | ||||
| WHERE { ?lover :loves ?beloved} |
|
|||
| WHERE { ?lover :loves _:beloved} |
|
|||
Semi-distinguished example
- Data (co-reference in data (could) show up in results):
:bob :loves _:x._:x :loves :bob._:y :loves :sally:sally :loves :sheevah.
| SELECT ?lover ?beloved | |||||||||||
| WHERE { ?lover :loves ?beloved} |
|
||||||||||
Oedipus Example
| SELECT ?x FROM <http://www.mindswap.org/ontologies/oedipus> | |||
| WHERE { ?x ns:hasChild [ rdf:type ns:Patricide; ns:hasChild ?y]. ?y rdf:type ns:NotPatricide.} |
NO RESULTS | ||
| WHERE { ?x ns:hasChild [ rdf:type ns:Patricide; ns:hasChild [ rdf:type ns:NotPatricide]]} |
|
||
(Example from the Description Logic Handbook, chapter 2.)
Oedipus in Detail
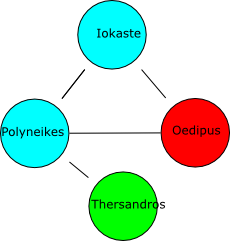
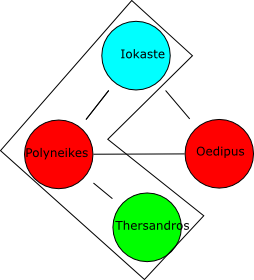
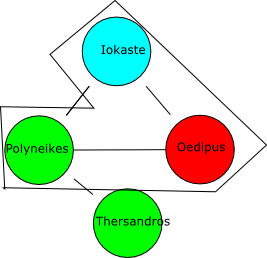
Reasoning by cases
- Iokaste hasChild Polyneikes, Oedipus
- Oedipus is a Parricide and Thersandros is not
- Polyneikes is either a Parricide or not a Parricide
Thoughts and Implications
- If ?y in the Oedipus query were semi-distinguished:
- What should its value be?
- Polyneikes or Thersandros?
- _:x instance of ({Polyneikes} or {Thersandros})?
- In the simple/RDF case:
- Entailment can only introduce redundant BNodes
- No disjunction
- The data could be non-lean
- How to treat existential bindings in the algebra?
- Scope of bindings?
- Redundancy?
Scoping
- Each answer has its own scope
- BNodes can co-refer within an answer
- No Bnode can co-refer between answers or tables
- Each table has its own scope
- BNodes can co-refer within tables
- BNodes cannot co-refer between tables
- This is the situation between querys (i.e., with result set documents)
- Each query has its own scope
- BNodes can co-refer anywhere through the query process
(but not between source graphs)
- Scope can transcend queries (e.g., during a session)
- User can take BNodes from an answer set to formulate a new query
Table Scoped
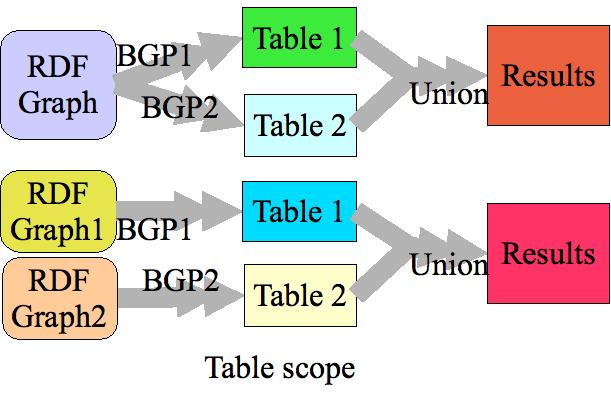
Table Scoped
| Data | BGPs | Tables | Results | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| _:x p a. _:x q a. _:x p _:y. _:y q b. |
{?sub p ?obj} |
|
|
||||||||||||||||
| {?sub q ?obj} |
|
No co-reference between _:f2 and _:f4
i.e., we don't know from
the answer set that
something (_:x) is related to something (_:y) that is related to b.
i.e., essentially we split the data into
two graphs: the p-related and the q-related.
Query Scoped

Query Scoped
| Data | BGPs | Tables | Results | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| _:x p a. _:x q a. _:x p _:y. _:y q b. |
{?sub p ?obj} |
|
|
||||||||||||||||
| {?sub q ?obj} |
|
Answer Redundancy
- Two modes of answering
- Normal and with DISTINCT
- Analogous to SQL's (usually implicit) ALL vs. DISTINCT
- Redundant answers vs. speed
- What amount of redundancy to allow in normal mode?
- No inherent upper bound (which RDBMSs have)
- Any answer entails infinite answers!
- Natural upper bound
- No more redundancy than is explicitly present in the data
- (plus what's introduced by the algebra)
- What determines that an answer set is DISTINCT (irredundant?)
- Many possible interpretations!
- Focus on answer subsumption
The Default Case (core)
- Key point:
- Only BNode redundancy introduced by entailment
- Easy cases
- All distinguished vars
- No BNodes in answers
- Thus, redundancy in data is a bound
- Distinguished + non-distinguished
- Name as good as Bnode for non-dist
- No (few) "link nodes" without explicit statement
- (Different in DLs, esp. with trans. roles)
- Semi-distinguished variables
- Think of BNodes as names ("told BNodes")
- Avoid leaning the graph
- Intuitive, but non-trivial to state
Equating Answers
- Answer subsumption vs. identity
- Identity requires the answers to be "exactly" the same
- But, does "01"^^xsd:integer == "1"^^xsd:integer?
- An answer subsumes another if the first "contains all the information" of the second
- With respect to the semantics of the data
- Generally, a URI or Literal subsumes a BNode
- Unless the BNode has a distinguishing co-reference
- WRT BNodes, three possibilities
- Source leanness
- Pairwise subsumption
- Answer set leanness
Source Leanness
- A table is source lean iff it is irredundant wrt term-equality and is an answer set for a BGP against a lean graph
- Query scoped BNodes make a big difference
- Answer 2 in the source lean results is subsumed by answer 1
- The projection introduced (at least apparent) redundancy
| Lean graph | Query (with proj) |
Normal Result | Source Lean | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| :bijan :loves
:mochi. :bijan :eats :mochi. _:aFool :hates :mochi. _:aFool :wants :mochi. |
SELECT ?x ?y {?x ?p ?y} |
|
|
||||||||||||||||
Pairwise Subsumption
- A table is pairwise lean iff no row subsumes any other row
- With answer level BNode scoping
| Non-lean graph | Query (with projection) |
Normal Result | Source Lean | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| :bijan :loves
:mochi. _:aFool :loves :mochi. _:aFool :wants :mochi. |
SELECT ?x ?y {?x ?p ?y} |
|
|
||||||||||||
Answer Set Leanness
- A table is lean iff no subset of rows subsumes any other subset rows
- Or, roughly, pairwise with answer set level BNode scoping
| Non-lean graph | Query (with projection) |
Normal Result | Source Lean | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| :bijan :loves
:mochi. :bijan :loves _:stuff _:aFool :loves _:x. _:x :wants :mochi. |
SELECT ?x ?y {?x ?p ?y} |
|
|
||||||||||||||||||
Relation to DISTINCT
- DISTINCT applies to the result/answer set of a query
- That is, to the final table
- DISTINCTing intermediate tables might change answers
- Which sense of table leanness to apply?
- Up for debate at the moment
- Source leanness (plus query scope) is very close to treating BNodes as names
- Easy to misinterpret
- Explanations would help
- Pairwise leanness is cheap, but strange
- Insensitive to BNode co-reference
- Answer set leanness close to lean CONSTRUCTed graphs
- Typically cheaper on a per-query basis than source leanness
- Source leanness computed only once
What do the Answers Mean?
- Consider counting
- Neither term-unequal BNodes nor term-unequal URIs indicate distinct entities
- I.e., every graph has the one-element simple model property
- If there is a model, there is a model with only one element
- Disregard literals for a moment
- Lack of any form of negation
- Traditional databases make the unique name assumption (UNA)
- Term-unequal terms denote distinct entities
- Thus, a model of a db must have as many entities as there
are terms (names)
- Thus DISTINCT answers do not indicate distinct entities
- Thus, any aggregation is suspect
A Bit about Value Testing
- Literals (including typed literals) have a fixed interpretation
- Which is not axiomatized in RDF
- They have their own equality theory
- Which affects DISTINCT
- There are other built in predicates
- Comparison operators
- These operators result in true, false, or error
- Ill-formed literals do not denote data values
- So "005"^^xsd:negativeInteger < 5 results in error
- Data values do not have to have literal form
- :x rdf:type xsd:negativeInteger
- :y rdf:type xsd:positiveInteger
- :x < :y ==??
Other bits
- There is a lot in SPARQL we didn't touch
- Graph variables
- Nested optionals
- Alternative result forms (CONSTRUCT, DESCRIBE, ASK)
- Ordering and chunking results
- Implementation techniques
- Issues with greater source expressiveness
- Complexity
- There is a lot which could end up in future SPARQL
- A more expanded protocol
- Aggregation and counting
- Path expression operators
- E.g., transitive closure
Thoughts
- RDF is odd
- An RDF graph is not a datastructure
- An RDF graph is not a normal database
- RDF(S) is a fairly weird logic
- SPARQL is odd
- Predecessors treat RDF as a normal database
- SPARQL struggles with this
- Powerful new features (e.g., graph variables)
- Designing an RDF++ query language is challenging!
- Even aside from politics
- Thinking of the future
- It would be nice to have a strongly analyzable query
language
- It would be nice to be able to "query the Web" in a robust way
Links
- Theory
- "The Logic of the Semantic Web" (presentation)
- "Semantics and Complexity of SPARQL"
- "A Semantic-aware RDF Query Algebra"
- Implementations
- The ESW Wiki has a fairly extensive list
- On line applications/demos
- The ESW Wiki has a list for these too
- The Data Access Working group home page has links to the specs as well as the (often) active mailing lists