
In recent years there has been an increased interest in the modelling and
recognition of human activities involving highly structured and semantically
rich behaviour such as dance, aerobics, and sign language. A novel approach is
presented for automatically acquiring stochastic models of the high-level
structure of an activity without the assumption of any prior
knowledge. The process involves temporal segmentation into plausible
atomic behaviour components and the use of variable length Markov
models for the efficient representation of behaviours. Experimental
results are presented which demonstrate the generation of realistic sample
behaviours and evaluate the performance of models for long-term temporal
prediction.
For more details see:
A. Galata, N. Johnson, D. Hogg, Int. Journal of Computer Vision and Image Understanding (CVIU), Vol. 81, No. 3, pp. 398-413, March 2001 ( .pdf).
Also available as a SCS technical report [gzip postscript] [pdf]
Figure 1 illustrates stochastic synthesis of sample behaviour using
the learnt behaviour model. An entirely hypothetical exercise routine sequence
has been generated and is used to animate a virtual humanoid using the
VRML modelling language.
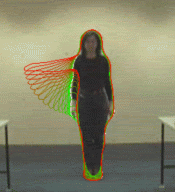
Figure 2 illustrates prediction of future behaviour at a selected time instant.
The learnt behaviour model is initially used in a recognition mode in order
to locate the appropriate model state given the observed behaviour up to
that time instant. Having located the current model state, prediction of
future behaviour is achieved by using the model either as a stochastic
or a maximum likelihood behaviour generator.

Back to Aphrodite's Home Page