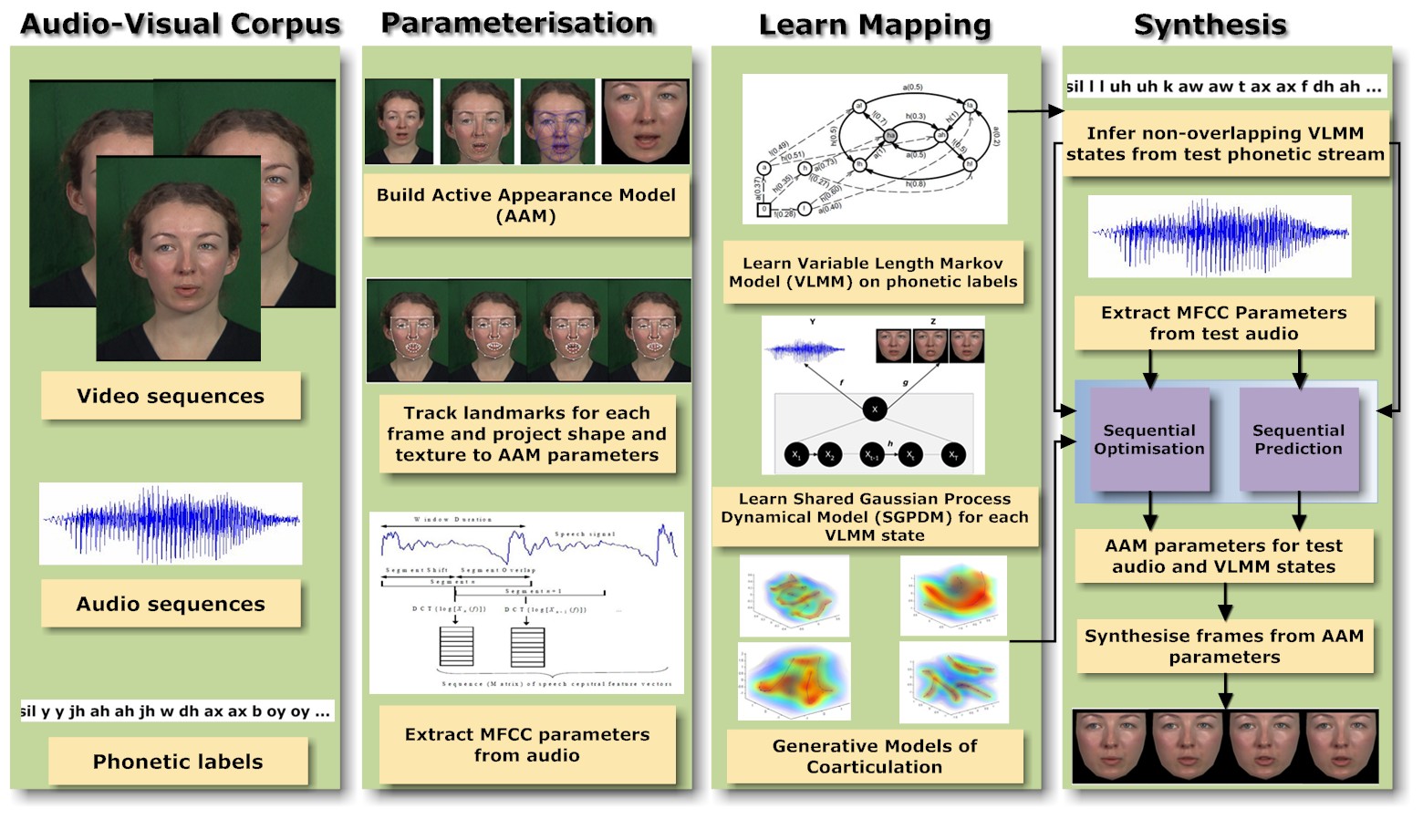
We present a novel approach to speech-driven facial animation using a non-parametric switching state space model based on Gaussian processes. The model is an extension of a shared Gaussian process dynamical model, augmented with switching states. Audio and visual data from a talking head corpus are jointly modelled using the proposed method. The switching states are found automatically using a variable length Markov model trained on labelled phonetic data. We also propose a synthesis technique that takes into account both previous and future phonetic context, thus accounting for coarticulatory effects in speech.
For more details see:
S. Deena, S. Hou and A. Galata "Visual Speech Synthesis by Modelling Coarticulation Dynamics using a Non-Parametric Switching State-Space Model", in Proc. International of the 12th International Conference on Multimodal Interfaces(ICMI-MLMI), 2010 ( .pdf ).

Fig. 1: Example one (movie) |

Fig. 2: Example 2 (movie) |
Back to Aphrodite's Home Page